


整体介绍
对于数据库而言,需要关注的侧重点有所改变,主要是一下几点:
- 技能掌握程度:熟练使用和掌握、熟悉数据库维护、熟悉数据库优化。
- 数据库常考点:基础概念、基础特性、SQL语句、存储引擎、索引、优化、集群分库分表、底层原理实现。
- 数据库掌握点:SQL语句、事务、存储引擎、索引、SQL优化、锁、日志、主从复制、读写分离、分库分表。
MySQL数据库教程主要分为三个部分:1.基础篇;2.进阶篇;3.运维篇。
- 基础篇中主要学习的内容有:MySQL概述、SQL、函数、约束、多表查询、事务。
- 进阶篇中主要学习的内容有:存储引擎、Linux安装MySQL、索引、SQL优化、视图/存储过程/触发器、锁、InnoDB核心、MySQL管理。
- 运维篇中主要学习的内容有:日志、主从复制、分库分表、读写分离。
基础篇
1. MySQL概述
1.1 数据库介绍
数据库涉及到的相关概念:
| 名称 | 全称 | 简称 |
|---|---|---|
| 数据库 | 存储数据的仓库,数据是有组织的进行存储 | DataBase(DB) |
| 数据库管理系统 | 操纵和管理数据库的大型软件 | DataBase Management System(DBMS) |
| SQL | 操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准 | Structured Query Language(SQL) |
主流数据库的排行榜:
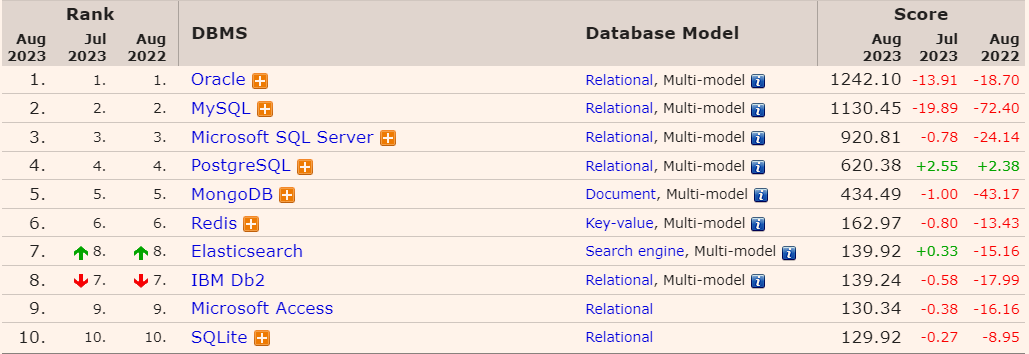
国内数据库的排行榜:
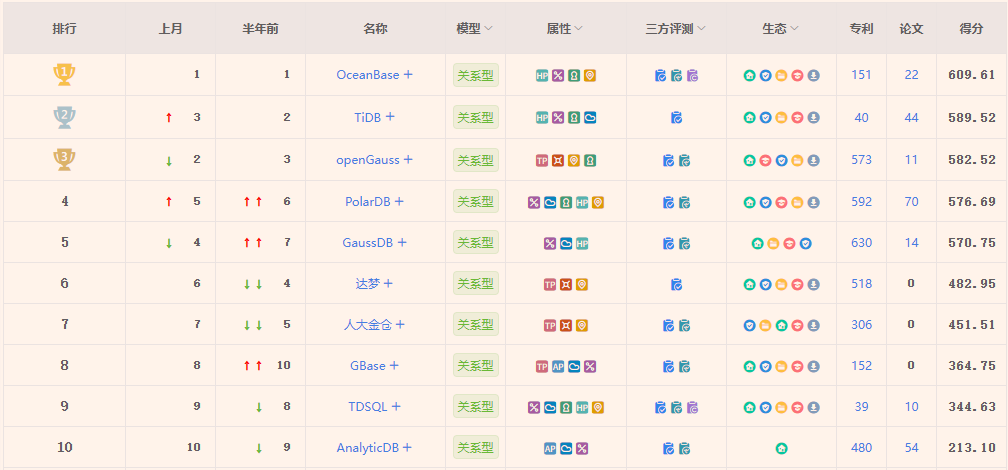
1.2 数据库下载
数据库下载地址: MySQL :: Download MySQL Installer
Windows 环境下,MySQL8.0.34下载地址: https://cdn.mysql.com//Downloads/MySQLInstaller/mysql-installer-community-8.0.34.0.msi
Windows 环境下,通过命令启动或停止MySQL服务:
# 开启MySQL服务
net start mysql服务名称
# 停止MySQL服务
net stop mysql服务名称
Windows 环境下,通过命令连接MySQL服务:
# 连接MySQL数据库 <-- 需要在系统环境中,给path配置上MySQL的bin目录
mysql [-h 127.0.0.1] [-p 3306] -u root -p
1.3 数据模型
用户操作:用户 -> DBMS -> DB;用户通过数据库管理系统(数据库软件)访问数据库的数据内容。
MySQL数据库属于关系型数据库(RDBMS)。
关系型数据库:建立在关系模型基础上,由多张相互连接二维表组成的数据。
关系型数据库的特点:
- 使用表存储数据,格式统一,便于维护
- 使用SQL语言操作,标准统一,使用方便
2. SQL
SQL语句可以单行或多行书写,以分号结尾
SQL语句可以使用空格/缩进来增强语句的可读性
MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
SQL语句的注释可以分为:单行注释和多行注释
- 单行注释:
-- 注释内容或# 注释内容(#号注释是MySQL特有) - 多行注释:
/* 注释内容 */
SQL语句的分类:DDL、DML、DQL、DCL
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
2.1 数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
MySQL的整数数值类型:
| 类型 | 大小 | 有符号(signed)范围 | 无符号(unsigned)范围 | 描述 |
|---|---|---|---|---|
| tinyint | 1 byte | (-128,127) | (0,255) | 小整数值 |
| smallint | 2 bytes | (-32768,32767) | (0,65535) | 大整数值 |
| mediumint | 3 bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| int/interger | 4 bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| bigint | 8 bytes | (-2^63,2^63-1) | (0,2^64-1) | 极大整数值 |
MySQL的浮点数数值类型:
| 类型 | 大小 | 有符号(signed)范围 | 无符号(unsigned)范围 | 描述 |
|---|---|---|---|---|
| float | 4 bytes | (-3.402823466 E+38,3.402823351 E+38) | 0,(1.175494351 E-38,3.402 823466 E+38) | 单精度浮点数值 |
| double | 8 bytes | (-1.7976931348623157 E+308,-2.2250738585072014 E-308),0,(2.2250738585072014 E-308,1.7976931348623157 E+308) | 0,(2.225073858507201 4 E-308,1.7976931348623157 E+308) | 双精度浮点数值 |
| decimal | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
MySQL的字符串类型:
| 类型 | 大小 | 描述 |
|---|---|---|
| char | 0 - 255 bytes | 定长字符串 |
| varchar | 0 - 65535 bytes | 变长字符串 |
| tinyblob | 0 - 255 bytes | 不超过255个字符的二进制数据 |
| tinytext | 0 - 255 bytes | 短文本字符串 |
| blob | 0 - 65535 bytes | 二进制形式的长文本数据 |
| text | 0 - 65535 bytes | 长文本数据 |
| mediumblob | 0 - 16777215 bytes | 二进制中等长度文本数据 |
| mediumtext | 0 - 16777215 bytes | 中等长度文本数据 |
| longblob | 0 - 4194967295 bytes | 二进制形式的极大文本数据 |
| longtext | 0 - 4194967295 bytes | 极大文本数据 |
MySQL的日期时间类型:
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| date | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| year | 1 | 1901 至 2155 | YYYY | 年份 |
| datetime | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestamp | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
2.2 DDL语句
DDL(Data Definition Language,数据定义语言),用来定义数据库对象(数据库, 表, 字段)。
数据库操作:
查询数据库:
# 查询所有数据库
show databases;
# 查询当前数据库
select database();
创建数据库:
create database [if not exists] 数据库名 [default charset 字符集] [collate 排序规则];
删除数据库:
drop database [if exists] 数据库名;
选择数据库:
use 数据库名;
数据库表操作:
查询数据库表:
# 查询当前数据库的所有表
show tables;
# 查询数据库表的字段信息
desc 表名;
# 查询数据库表的建表语句
show create table 表名;
创建数据库表:
create table 表名(
字段1 字段1类型 [comment 字段1注释],
字段2 字段2类型 [comment 字段2注释],
字段3 字段3类型 [comment 字段3注释],
...
字段n 字段n类型 [comment 字段n注释],
)[comment 表注释];
修改数据库表名:
alter table 表名 rename to 新表名;
删除数据库表:
# 包含数据库表结构
drop table [if exists] 表名;
# 保留数据库表结构
truncate table 表名;
数据库表字段操作:
添加数据库表字段:
alter table 表名 add 字段名 类型(长度) [comment 字段注释] [约束];
修改数据库表字段:
# 修改数据库表字段类型
alter table 表名 modify 字段名 新数据类型(长度);
# 修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 字段注释] [约束];
删除数据库表字段:
alter table 表名 drop 字段名;
2.3 DML语句
DML(Data Manipulation Language,数据操作语言),用来对数据库表中的数据进行增删改(insert、update、delete)。
添加数据库表数据:
# 给指定的字段添加数据
insert into 表名 (字段名1,字段名2,...) values (值1,值2,...)
# 给全部字段添加数据
insert into 表名 values (值1,值2,...);
# 批量给某些字段添加数据值
insert into 表名 (字段名1,字段名2,...) values (值1,值2,...),(值1,值2,...),(值1,值2,...);
# 批量添加所有字段的值
insert into 表名 values (值1,值2,...),(值1,值2,...),(值1,值2,...);
添加数据时,指定的字段顺序需要与值的顺序一一对应;字符串和日期类型的数据应该包含在引号中;插入的数据大小,应该在字段的规定范围内。
修改数据库表数据:
update 表名 set 字段名1 = 值1, 字段名2 = 值2,... [where 条件];
修改数据时,修改的条件可以有、也可以没有;如果没有条件,则会修改整张表的所有数据。
删除数据库表数据:
delete from 表名 [where 条件];
删除数据时,删除的条件可以有、也可以没有;如果没有条件,则会删除整张表的所有数据。
删除的语句不能删除某个字段,如果要删除某个字段可以使用update修改该字段的值为默认空状态。
2.3 DQL语句
DQL(Data Query Language,数据查询语言),用来查询数据库表中表的记录(select)。
查询数据库表记录的编写的语法格式:
select 字段列表 from 表名列表
where 条件列表
group by 分组字段列表 having 分组后条件列表
order by 排序字段列表
limit 分页参数
查询并展示多个字段:
# 查询某些字段列
select 字段1,字段2,字段3,... from 表名;
# 查询所有字段列
select * from 表名;
查询结果设置别名:
select 字段1 [as 别名1],字段2 [as 别名2],... from 表名;
查询结果进行去重展示:
select distinct 字段列表 from 表名;
查询结果进行条件筛选展示:
select 字段列表 from 表名 where 条件列表;
条件列表里可以分为逻辑运算符和比较运算符;逻辑运算符是连接每个条件,而比较运算符是每个条件的筛选依据。
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且(多个条件同时成立) |
| or 或|| | 或者(多个条件任意一个成立) |
| not 或 ! | 非,不是 |
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between … and … | 在某个范围之内(含最小值,最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| is null | 匹配的字段值为null |
查询结果进行聚合函数计算展示:
select 聚合函数(字段列表) from 表名;
聚合函数是将一列数据作为一个整体,进行纵向计算,所有的null值是不参与计算。
常见的聚合函数如下表格所示:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
查询结果进行分组展示:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]
此处,where 和 having是有所区别的,主要区别有以下两点:
- 执行时机不同:
where是在分组之前进行过滤,不满足where条件的,是不进行参与分组;having是在分组之后,对分组之后的结果进行过滤。 - 判断条件不同:
where不能对聚合函数进行判断;而having可以对聚合函数的结果进行判断。
where、聚合函数、having三者执行顺序:where > 聚合函数 > having
一般情况下,分组之后,查询的字段为聚合函数和分组字段。如果为其它字段,可能无任何意义。
查询结果进行排序展示:
select 字段列表 from 表名 order by 字段1 排序方式1, 字段2 排序方式2;
排序方式有两种:ASC - 升序(默认值);DESC - 降序。
多个字段进行排序时,当第一个字段相同时,才会根据第二个字段进行排序。
查询结果进行分页展示:
select 字段列表 from 表名 limit 起始索引,查询记录数;
起始索引从0开始,*起始索引=(查询页码 - 1)每页显示记录数。
分页查询时数据库的方言,不同的数据库有不同的实现。
MySQL中的分页查询标识是 limit。如果查询的是第一页数据,起始索引是可以省略的。简写为 limit 10。
DQL编写顺序和DQL的执行顺序比较:
DQL编写顺序:select 字段列表、from 表名列表、where 条件列表、group by 分组字段列表 having 分组后条件列表、order by 排序字段列表、limit 分页参数。
DQL执行顺序:from 表名列表、where 条件列表、group by 分组字段列表 having 分组后条件、select 字段列表、order by 排序字段列表、limit 分页参数。
2.5 DCL语句
DCL(Data Control Language,数据控制语言),用来管理数据库用户、控制数据库的访问权限
数据库的用户操作:
查询数据库的所有用户:
# 进入mysql数据库
use mysql;
# 访问mysql数据库的user数据库表
select * from user;
创建数据库的用户:
create user '用户名'@'主机名' identified by '密码';
修改数据库的用户密码:
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码';
删除数据库的用户:
drop user '用户名'@'主机名';
数据库的用户权限操作:
查看用户具有的权限:
show grants for '用户名'@'主机名';
授予用户的某些权限:
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
撤销用户的某些权限:
revoke 权限列表 on 数据库名.表名 to '用户名'@'主机名';
在授予或撤销用户权限时,存在多个权限用 , 分割;数据库名和表名可以使用 * 进行通配,代表所有数据库或者数据库表。
3. 函数
函数是指一段可以直接被另一段程序调用的程序或者代码。
MySQL中执行函数的方法:select 函数(参数)
MySQL中的函数主要分为:字符串函数、数值函数、日期函数、流程函数。
3.1 字符串常用函数
| 函数名称 | 功能 |
|---|---|
| CONCAT(s1,s2,…,sn) | 字符串拼接,将s1,s2,…sn拼接成一个字符串 |
| LOWER(str) | 将字符串str全部转为小写 |
| UPPER(str) | 将字符串str全部转为大写 |
| LPAD(str,n,pad) | 左填充,用字符串pad对str左边进行填充,达到n个字符串长度 |
| RPAD(str,n,pad) | 右填充,用字符串pad对str右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str,start,len) | 返回从字符串str从start位置起的len个长度的字符串 |
3.2 数值常用函数
| 函数名称 | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x,y) | 返回x/y的模 |
| RAND() | 返回0-1内的随机数 |
| ROUND(x,y) | 将参数x的四舍五入的值,保留y位小数 |
3.3 日期常用函数
| 函数名称 | 功能 |
|---|---|
| CURDATA() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定date的年份 |
| MOUTH(date) | 获取指定date的月份 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDIFF(date1,date2) | 返回起始时间date1和结束时间date2之间的天数 |
3.4 流程函数
在SQL语句中实现条件筛选,从而提高语句的执行效率。
| 函数名称 | 功能 |
|---|---|
| IF(value,t,f) | 如果value为true,则返回t,否则返回f |
| IFUNLL(value1,value2) | 如果value1不为NULL,返回value1,否则返回value2 |
| CASE WHEN [expr1] THEN [res1] … ELSE [default] END | 如果expr1为true,返回res1,… 否则返回default默认值 |
| CASE [expr] WHEN [val1] THEN [res1] … ELSE [default] END | 如果expr的值等于val1,返回res1,…否则返回default默认值 |
4. 约束
约束是作用于数据库表字段上的规则,用于限制存储在数据库表中的数据。主要是保障数据库中数据的正确性、 有效性和完整性。
约束的类型:
| 约束名称 | 功能 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY 自增:AUTO_INCREMENT |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束(8.0.16版本之后) | 保证字段值满足一个条件 | CHECK |
| 外键约束 | 用于两张表的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY |
约束主要是作用于数据库表字段上,因此,在创建表/修改表的时候均可以添加相应的约束条件。
从使用对象的角度可以将约束划分为:数据库表本身约束和数据库表外键约束。
数据库表本身约束:是用于自身数据表,单表内部的约束条件。包含约束有:非空约束、唯一约束、主键约束、默认约束、检查约束。
数据库表外键约束:是用于两张数据表之间的关联,保障数据的一致性和完整性
添加数据库表外键:
# 创建表的时添加外键
create table 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段) REFERENCES 主表(主表列名)
);
# 单独添加表的外键
alter table 表名 add contraint 外键名称 foreign key (外键字段名) references 主表(主表列名);
添加外键的更新/删除行为:
alter table 表名 add constraint 外键名称 foreign key (外键字段名) references 主表(主表列名) on update 更新行为 on delete 删除行为;
更新/删除的行为:
| 行为关键字 | 描述 |
|---|---|
| NO ACTION | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。(与RESTRICT一致) |
| RESTRICT | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。(与NO ACTION一致) |
| CASCADE | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则也删除/更新外键在子表中的记录 |
| SET NULL | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为NULL(要求子表中该外键不能设置为非空约束) |
| SET DEFAULT | 父表有变更时,子表将外键列设置成一个默认的值(Innodb不支持) |
5. 多表查询
由于表与表之间根据实际的需求及模块之间的关系,所以存在了以下三种关系:
- 一对多(多对一):实现方式 -> 在多的一方建立外键,指向一的一方的主键。
- 多对多:实现方式 -> 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键。
- 一对一:实现方式 -> 在任意一方加入外键,关联另一方的主键,并设置外键为唯一约束
unique。
多表查询是指从多张表中查询数据。但查询结果会产生笛卡尔积,为了保证数据的有效性,需要消除无效的笛卡尔积。
笛卡尔积是指在数学中A、B两个集合的所有组合情况。
多表查询的分类:
- 连接查询
- 内连接:相当于查询A、B集合的交集部分数据。
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据。
- 右外连接:查询右表所有数据,以及两张表交集部分数据。
- 自连接:当前表与自己的连接查询,自连接必须使用表别名
- 子查询:标量子查询、列子查询、行子查询、表子查询
5.1 内连接
内连接:查询多张表的交集部分
内连接查询的语法格式:
# 隐式内连接
select 字段列表 from 表1,表2 where 条件...;
# 显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件...;
5.2 外连接
外连接查询的语法格式:
# 左外连接: 相当于查询表1(左表)的所有数据,包含表1和表2交集部分的数据
select 字段列表 from 表1 left [outer] join 表2 on 条件...;
# 右外连接: 相当于查询表2(右表)的所有数据,包含表1和表2交集部分的数据
select 字段列表 from 表1 right [outer] join 表2 on 条件...;
5.3 自连接
自连接查询,可以是内连接查询,也可以是外连接查询
自连接查询的语法格式:
select 字段列表 from 表1 别名1 join 表1 别名2 on 条件...;
5.4 联合查询
union、union all查询,是把多次查询的结果合并起来,形成一个新的查询结果集
联合查询的多表的列数和字段类型必须保持一致。
union 和 union all 之间的区别:
union会对合并之后的数据进行去重。union all会将全部的数据直接合并在一起。
联合查询的语法格式:
select 字段列表 from 表1...
union [all]
select 字段列表 from 表2...;
5.5 子查询
子查询,又称为嵌套查询,SQL语句中嵌套SELECT语句
子查询的一般语法格式:
select * from t1 where column1 = (select column1 from t2);
子查询外层的语句可以是 insert / update / delete / select 的任意一个。
根据子查询的结果可以分为:
- 标量子查询:子查询结果为单个值。
- 列子查询:子查询结果为一列。
- 行子查询:子查询结果为一行。
- 表子查询:子查询结果为多行多列。
根据子查询位置可以分为:
- 在
where之后 - 在
from之后 - 在
select之后
标量子查询:
子查询返回的结果是单个值(数字、 字符串、 日期等),是单一最简单的形式,这种子查询称为标量子查询。
常用的操作符:=、<>、>、>= 、< 、<=
列子查询:
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:in、not in、any、some、all
| 操作符号 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足条件即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
行子查询:
行子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:=、<>、in、not in
表子查询:
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:in
6. 事务
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体向系统提交或撤销请求,即这些操作要么同时成功,要么同时失败。
MySQL的事务在默认情况下是自动提交的。即当执行一条DML语句,MySQL会立即隐式的提交事务。
MySQL事务操作命令:
- 开启事务:
start transaction或begin - 提交事务:
commit - 回滚事务:
rollback
事务的四大特性:
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须是所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据改变就是永久的。
事务并发时遇到的问题:
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据之前,又发现这行数据已经存在了,好像出现了幻影 |
事务隔离级别:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read(默认) | × | × | √ |
| Serializable | × | × | × |
MySQL中事务的查看和设置:
-- 查看事务隔离级别
select @@transaction_isolation;
-- 设置事务隔离级别
set [session|global] transaction isolation level [read uncommitted|read committed|repeatable read|serializable];
进阶篇
1. 存储引擎
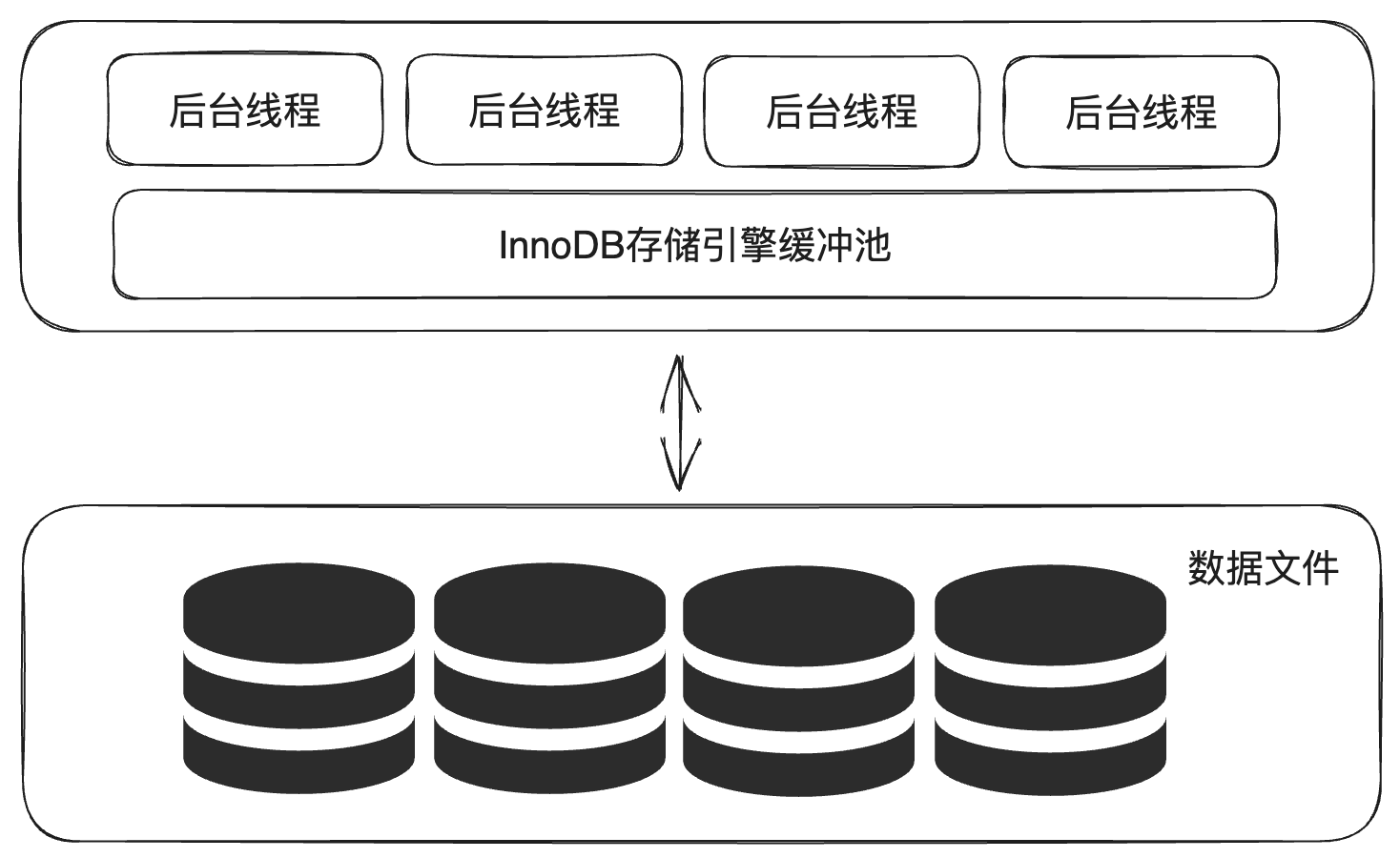
1.1 体系结构
MySQL的体系结构如下图所示:
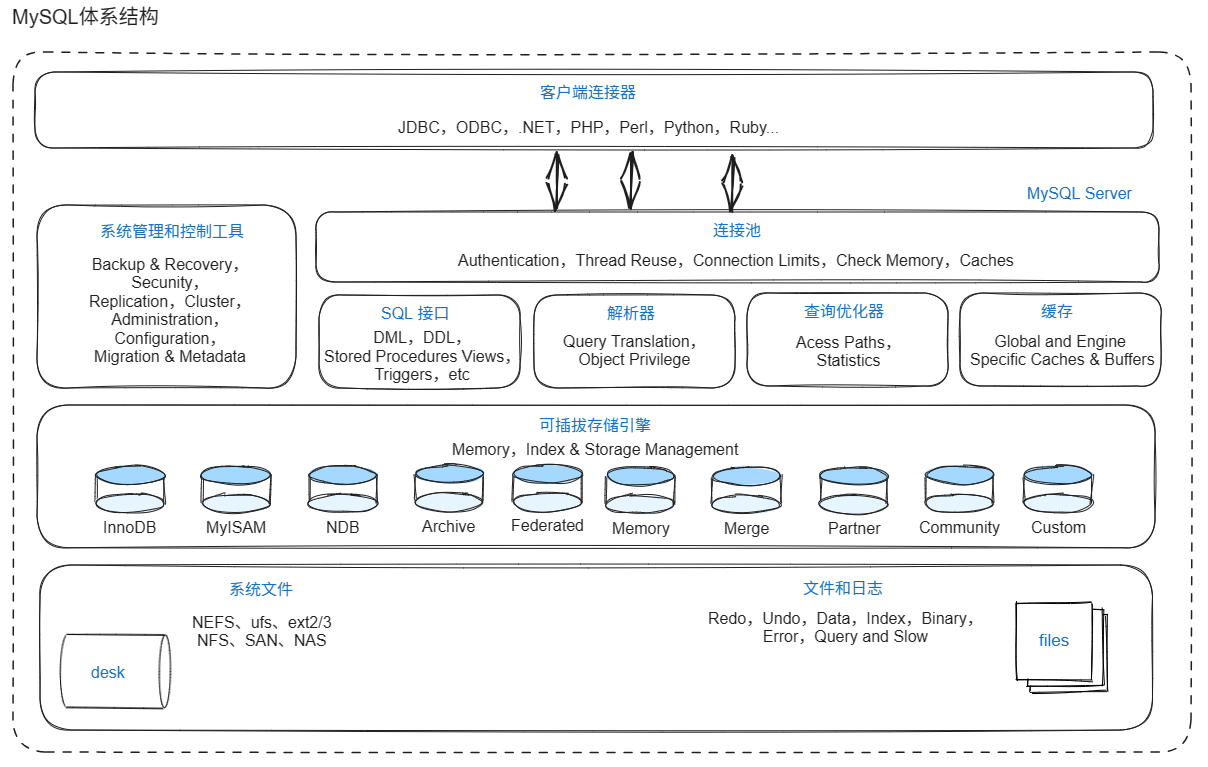
连接层是处在最上层一些客户端和连接服务,主要完成一些类似于连接处理、授权认证及相关的安全方案。服务器也会为安全接入每个客户端验证它所具有的操作权限。(连接池)
服务层是主要完成大多数核心服务功能,如SQL接口、缓存的查询、SQL的分析和优化、部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程函数等。(SQL接口、解析器、查询优化器、缓存)
引擎层是真正的负责MySQL中数据的存储和读取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,可以根据实际情况,来选择合适的存储引擎。(可插拔式存储引擎)
存储层是将数据存储在文件系统上,并完成与存储引擎的交互。(系统文件、文件和日志)
1.2 存储引擎
存储引擎是存储数据、建立索引、更新/查询数据等技术的实现方式。
存储引擎是基于数据库表的,而不是基于数据库的,所以存储引擎也成为表类型。
声明存储引擎,在创建表的时候:
create table 表名(
字段1 字段1类型 [comment 字段1注释],
...
字段n 字段n类型 [comment 字段n注释]
)engine = innodb [comment 表注释];
查看当前MySQL数据库支持的存储索引:
show engines;

上图是在8.0.30数据库中查询的结果。主要关注的存储引擎有:InnoDB、MyISAM、MEMORY。
InnoDB存储引擎:
InnoDB存储引擎是一种兼顾高可靠和高性能的通用存储引擎,在MySQL5.5之后,InnoDB是默认MySQL存储引擎。
InnoDB存储引擎的特点:
- DML操作遵循ACID特性,支持事务。
- 行级锁,提高并发访问性能。
- 支持外键FOREIGN KEY约束,保证数据的完整性和正确性。
InnoDB存储引擎文件格式:xxx.ibd文件 -> xxx代表的表名。
InnoDB存储引擎在MySQL8.0以上的版本是每张表都会对应一个 xxx.ibd 的表文件,存储该表的表结构(frm - 早期, sdi)、 数据和索引。配置参数: innodb_file_per_table
-- 查看 innodb_file_per_table 参数值
show variables like 'innodb_file_per_table';
在InnoDB存储引擎下,通过存储的ibd文件查看表结构信息的命令:ibd2sdi ibd文件(在命令行终端执行)
InnoDB逻辑存储结构:表空间(TableSpace)-> 段(Segement)-> 区(Extent)-> 页(Page)-> 行(Row)。
- 行(Row):有Trx id, Roll pointer, col...;存储事务ID,回滚指针,列信息。
- 页(Page):磁盘操作的最小单元,固定大小16k。
- 区(Extent):固定大小1M。
MyISAM存储引擎:
MyISAM存储引擎是MySQL早期的默认存储引擎。
MyISAM存储引擎的特点:
- 不支持事务,不支持外键
- 支持表锁,不支持行锁
- 访问速度快
MyISAM存储引擎文件格式:xxx.sdi -> 存储表结构信息;xxx.MYD -> 存储数据;xxx.MYI -> 存储索引。
MEMORY存储引擎:
MEMORY存储引擎的表数据存储在内存中,由于受到硬件问题、 断电问题的影响,只能将这些表作为临时表或缓存使用。
MEMORY存储引擎特点:
- 内存存放
- hash索引(默认)
MEMORY存储引擎文件格式:xxx.sdi -> 存储表结构信息。
InnoDB、MyISAM和MEMORY之间的对照关系:
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
InnoDB、MyISAM、Memory存储引擎应用场景:
InnoDB存储引擎是MySQL默认的存储引擎,支持事务、外键。适用于对于事物的完整性有比较高的要求;在并发条件下要求数据的一致性;数据除了插入和查询之外,还包含很多的更新、删除操作。
MyISAM存储引擎适用于以读写操作和插入操作为主,只有很少的更新和删除操作;对事物的完整性、并发性要求不是很高。(可以选择MongoDB代替)
MEMORY存储引擎适用于将所有数据保存在内存中,访问速度快。通常用于临时表及缓存。MEMORY的缺陷是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。(可以使用Redis替代)
2. Linux安装MySQL
Linux环境为: CentOS8.2 X86架构下,MySQL版本: 8.0.34
MySQL的目录规划:
- 根目录: /mysql/
- 安装包目录: /mysql/install/
- 安装目录: /mysql/mysql8.0/
CentOS8.2 X86环境下,安装MySQL8.0.34:
步骤1:下载MySQL的rpm包
MySQL的rpm包下载页面: MySQL :: Download MySQL Community Server
MySQL的8.0.34 rpm包下载链接: https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.34-1.el8.x86_64.rpm-bundle.tar
步骤2:上传MySQL的rpm安装包至MySQL安装包目录
# 进入MySQL安装包目录
cd /mysql/install/
# 上传rpm安装包, 通过rz选择本机的rpm包进行上传(实现linux和windows之间的文件传输)
rz
步骤3:解压MySQL的rpm安装包至MySQL安装目录
tar -zxf mysql-8.0.34-1.el8.x86_64.rpm-bundle.tar -C /mysql/mysql8.0
步骤4:安装MySQL的rpm安装包
解压之后各rpm包的含义如下:
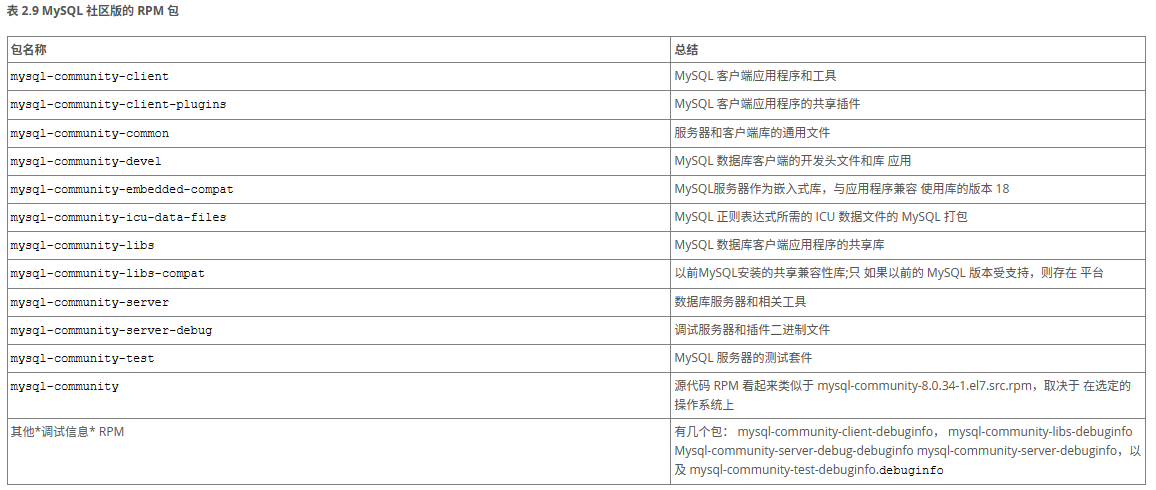
必须安装的rpm包如下:
# 进入MySQL安装目录
cd /mysql/mysql8.0/
# 按照下列顺序一次安装rpm包
rpm -ivh mysql-community-common-8.0.34-1.el8.x86_64.rpm
rpm -ivh mysql-community-client-plugins-8.0.34-1.el8.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.34-1.el8.x86_64.rpm
rpm -ivh mysql-community-icu-data-files-8.0.34-1.el8.x86_64.rpm
rpm -ivh mysql-community-client-8.0.34-1.el8.x86_64.rpm
rpm -ivh mysql-community-server-8.0.34-1.el8.x86_64.rpm
可选安装的rpm包如下:
# 安装mysql-community-debuginfo
rpm -ivh mysql-community-debuginfo-8.0.34-1.el8.x86_64.rpm
# 安装mysql-community-server-debug
rpm -ivh mysql-community-server-debug-8.0.34-1.el8.x86_64.rpm
# 安装mysql-community-devel
rpm -ivh mysql-community-devel-8.0.34-1.el8.x86_64.rpm
# 安装mysql-community-test
rpm -ivh mysql-community-test-8.0.34-1.el8.x86_64.rpm
步骤5:启动MySQL系统服务
# 启动MySQL服务
systemctl start mysqld
# 开机自启MySQL
systemctl enable --now mysqld
步骤6:查看MySQL的root用户临时密码
通过rpm包安装的MySQL,在控制台是没有日志信息。MySQL的日志信息在/var/log/mysqld.log
grep 'temporary password' /var/log/mysqld.log
步骤7:修改root用户临时密码
# 使用临时密码登录MySQL数据库
mysql -u root -p
# 修改root密码
alter user 'root'@'localhost' identified by 'root新密码';
-- 查看当前密码策略
show variables like 'validate_password.%';
MySQL远程访问配置:
步骤1:配置root的远程连接信息
-- 创建远程用户信息
create user 'root'@'%' identified with mysql_native_password by '远程访问密码';
-- 授予该远程用户的相关权限,这里默认所有的权限,所有表空间
grant all privileges on *.* to 'root'@'%';
步骤2:测试远程访问MySQL
MySQL安装信息:
通过上述操作步骤后,可以进行远程访问MySQL数据库。MySQL数据库安装的相关信息如下:
- 数据库目录: /var/lib/mysql/
- 配置文件目录: /usr/share/mysql-8.0/
- MySQL系列命令目录: /usr/bin/
- my.cnf文件路径: /etc/my.cnf
- 数据存储目录: /var/lib/mysql/
3. 索引
索引(index)是帮助MySQL高效获取数据和数据结构(有序)。在数据之外,数据库还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据。通过这些引用就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
对比未使用索引的数据而言,使用索引的优缺点如下:
| 优点 | 缺点 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列也是需要占用空间的 |
| 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗 | 索引大大提高了查询效率,同时却降低了更新表的速度,如对表进行 insert、update、delete时,效率降低 |
3.1 索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有着不同的结构,主要包含以下几种:
- B+ tree 索引:常见的索引类型,大部分引擎都支持B+树索引。
- Hash 索引:底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才是有效的,不支持范围查询。
- R-tree(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。
- Full-text(全文索引):是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene、 Solr、 ES。
上述四种索引类型在InnoDB、 MyISAM、 MOMERY三种存储引擎中支持情况:
| 索引 | Innodb | MyISAM | Memory |
|---|---|---|---|
| B+ Tree 索引 | 支持 | 支持 | 支持 |
| Hash 索引 | - | - | 支持 |
| R-tree(空间索引) | - | 支持 | - |
| Full-text(全文索引) | 5.6版本之后支持 | 支持 | 支持 |
一般默认情况下,在MySQL中所说的索引,是指的B+ tree组织的索引
B+ tree 索引:
B+ tree的演变过程:
- 二叉树:顺序插入时,会形成一个链表,查询性能会大大降低。大量数据情况下,层级较深,检索速度慢。
- 红黑树(自发形成二叉树):大数据量情况下,层级较深,检索速度慢。
- B- tree(多路平衡二叉树):每个节点最多可以存最大度数(max-degree)-1个KEY。即每个节点的数据个数/key=最大度数 - 1,每个节点的指针树<= 最大度数。
- B+ tree(是B- tree的变种):与B- tree的区别: a. 所有的数据都会出现在叶子节点; b. 叶子节点形成一个单向链表。
MySQL中索引结构对B+ tree进行了优化,在原本B+ tree的基础上,增加一个指向相邻叶子节点的链表指针,这样就形成了带有顺序指针的B+ tree,提高了区间访问的性能。
Hash 索引:
哈希索引就是采用一定的Hash算法,将键值换算成新的Hash值,映射到对应的槽位上,然后存储在Hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,它们就产生了Hash冲突(也就称为Hash碰撞)。Hash碰撞可以通过链表解决。
Hash索引的特点:
- Hash索引只能用于对比比较(
=、in),不支持范围查找(between,>,<,...)。 - 无法利用Hash索引完成排序操作
- 查询效率高,通常只需要一次检索就可以,效率通常高于B+ tree索引。
MySQL中,支持Hash索引的是MEMORY存储引擎,而InnoDB存储引擎具有自适应Hash功能。B+ tree索引会在在指定条件下自动构建。
InnoDB存储引擎选择使用B+ tree索引结构的原因:
- 相对于二叉树而言,B+ tree层级更少,搜索效率更高。
- B- tree的叶子节点和非叶子节点都会保存数据。所以如果使用B- tree,会导致一页中存储的键值减少,指针也会随之减少,要想与B+ tree保持同等量的数据,只能增加树的高度,会导致性能降低。
- 相对于Hash索引,B+ tree支持范围匹配和排序操作。
3.2 索引分类
MySQL中索引分类:
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表某个数 | 可以有多个 | UNIQUE |
| 常规索引 | 快读定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引的值 | 可以有多个 | FULLTEXT |
在InnoDB存储引擎中,按照索引的存储形式,可以分以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储和索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以有多个 |
在InnoDB存储引擎中,聚集索引在每个数据库表的选取规则:
- 如果该数据库表中存在主键,则主键索引就是聚集索引。
- 如果该数据库表中不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果该数据库表中既没有主键也没有合适的唯一主键索引,则InnoDB存储引擎会自动生成一个rowid作为隐藏的聚集索引。
数据库表查询可能会涉及到回表查询。回表查询:先通过二级索引查询出当前行的主键值,再通过聚集索引查询当前行数据。
3.3 索引操作
创建表索引:
create [unique|fulltext] index index_name on table_name(index_col_name,...);
查看表索引:
show index from table_name;
删除表索引:
drop index index_name on table_name;
3.4 SQL性能分析
是否使用索引、 索引效率的优劣都需要一定的指标进行衡量和体现
- SQL执行频率
- 慢查询日志
- profile详情
- explain执行计划
SQL执行频率:
在MySQL客户端中,通过 show [session|global] status 命令可以查看服务器状态信息。通过 show global status like 'Com______' 命令,来查看当前数据库的 INSERT、UPDATE、DELETE、SELECT的访问频次。
show global status like 'Com_______';
慢查询日志:
慢查询日志主要是记录了所有执行时间超过指定时间(long_query_time,单位: 秒,默认10秒)的所有SQL语句的日志。
在MySQL中,慢查询日志默认是关闭的(查看状态:show variables like 'slow_query_log'),需要在MySQL的配置文件my.cnf中进行配置。
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
对MySQL的配置文件my.cnf配置完成后,需要重启MySQL服务器(重启命令:systemctl restart mysqld),所有慢查询的日志记录在/var/lib/mysql/localhost-slow.log文件中。
profile详情:
profile详情能够在SQL优化时帮助了解SQL执行在各阶段的情况。在MySQL中,profile默认情况下时关闭的。
查看profile状态:
select @@have_profiling;
开启profile,通过set语句在session/global级别开启profiling:
set profiling = 1;
查看profile记录的信息:
-- 查看每一条SQL的耗时基本情况
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
explain执行计划:
在SQL查询时,判断当前SQL的优化粒度。explain/desc sql语句会对当前执行的SQL进行解析,并返回以下字段:
| 字段名 | 含义 |
|---|---|
| id | select 查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行) |
| select_type | 表示select的类型,常见的取值有:SIMPLE(简单表,即不适用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等 |
| type | 表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、index、all |
| possible_key | 显示可能应用在这张表上的索引,一个或多个 |
| Key | 实际使用的索引,如果为NULL,则没有使用索引 |
| Key_len | 表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,再不巡视精确性的前提下,长度越短越好 |
| rows | MySQL认为必须要查询的行数,在InnoDB引擎的表中,是一个估计值,可能并不是准确的 |
| filtered | 表示返回结果的行数占读取行数的百分比,filtered的值越大越好 |
| Extra | 额外信息,在优化过程中也需要参考 |
3.5 索引使用
最左前缀法则:
如果使用了联合索引,在使用时,需要遵循最左前缀法则。
最左前缀法则是指从查询索引的最左列开始,不跳过索引中的某一列。如果存在跳跃某一列时,索引将会从跳过的字段后面索引失效。
特例:查询索引的列的顺序可以不对应,只要所有查询索引的列都存在即可,且没有其它字段。
范围查询:
在联合索引中,出现范围查询(>、<)时,范围查询右侧的列表就会失效。如果想使用,尽可能在业务允许的情况下使用≥、≤进行判断。
索引列运算:
不能在索引列上进行运算操作,否则索引将会失效。
字符串不加引号:
字符串类型字段使用时,不加引号,索引将会失效。
模糊查询:
如果仅仅是尾部模糊匹配,索引不会失效。
如果是头部模糊匹配,索引将会失效。
or连接条件:
用or分隔开的条件,如果or前的条件中的所有列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
用or分隔开的条件,如果or前后的都有使用索引,那么该SQL就是会使用索引。
数据分布影响:
如果MySQL评估使用索引比全表慢,则不使用索引。
SQL提示:
SQL提示是优化数据库的一个重要的干预手段。简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的
建议使用某个索引:
select 字段列 from 表名 use index(索引名) where 字段列 比较/逻辑符号 字段值
忽略使用某个索引:
select 字段列 from 表名 ignore index(索引名) where 字段列 比较/逻辑符号 字段值
强制使用某个索引:
select 字段列 from 表名 force index(索引名) where 字段列 比较/逻辑符号 字段值
覆盖索引:
尽量使用覆盖索引(查询使用索引,并且需要返回的列,在该索引中已经全部能够找到),减少全字段查询。
使用了覆盖索引并且不需要查询索引外的其它字段时,会在explain执行计划中的Extra字段中显示: using where;using index(不需要回表查询)。
使用了覆盖索引但是还需要查询索引外的其它字段时,会在explain执行计划中的Extra字段中显示: using index condition(需要回表查询)。
前缀索引:
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,索引时也会浪费大量的磁盘IO,影响查询效率。此时就可以将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
创建前缀索引:
-- n代表前缀的个数
create index 索引名 on 表名(列名(n));
前缀长度n:可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高查询效率则也越高。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
-- 全长度的索引选择性
select count(distinct 字段列)/count(字段列) from 表名;
-- 前n长度的索引选择性
select count(distinct strsub(字段列,0,n))/count(字段列) from 表名;
单列索引与联合索引:
- 单列索引:即一个索引只包含单个列
- 联合索引:即一个索引包含了多个列
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询。
联合索引的数据结构是根据联合索引创建的顺序,如果前一个相同,则按照后一个排序。依次进行。
3.6 索引设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引
- 针对于常作为查询条件
where、排序order by、分组group by操作的字段建立索引 - 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,在创建表时使用NOT NULL约束。当优化器知道每一列是否包含NULL值时,可以更好地确定哪个索引最有效的用于查询
4. SQL优化
4.1 插入数据
批量插入数据,一般一次最多不要超过1000条:
insert into 表名 values(字段列1,字段列2,...,字段列n);
手动提交事务:
start transaction;
insert into 表名 values(字段列1,字段列2,...,字段列n);
insert into 表名 values(字段列1,字段列2,...,字段列n);
insert into 表名 values(字段列1,字段列2,...,字段列n);
...
insert into 表名 values(字段列1,字段列2,...,字段列n);
commit;
主键顺序插入:
-- 主键乱序插入:10,3,5,1,2,9,7,6,4,8
-- 主键顺序插入:1,2,3,4,5,6,7,8,9,10
-- 主键顺序插入的效率 > 主键乱序插入
大批量插入数据: 如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时就可以使用MySQL数据库提供的load指令。
-- 客户端连接数据库服务时,加上参数 --local-infile
mysql -u root -p --local-infile
-- 查看数据库是否打开--local-infile参数(默认:0,关闭)
select @@local_infile;
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile=1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile 'sql文件路径' into table '表名' fields terminated by '行内分割符号' lines terminated by '行间分割符号'
4.2 主键优化
数据组织方式:
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table,IOT)。
页分裂:
页可以为空,也可以填充一半,也可也填充100%。每个页包含了2 - N行数据(如果一行数据过大,就会行溢出),根据主键排列。页分裂主要存在主键乱序插入的情况。
页合并:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除,并且它的空间变得允许被其它记录声明使用。
当页中删除的记录达到MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找靠近的页(前或后),看看是否可以将两个页合并以优化空间使用。
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或创建索引时指定。
主键设计原则:
- 满足业务需求的情况下,尽量降低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
- 尽量不要使用UUID做主键或者是其它自然主键,如身份证号,会导致二级索引的存储过大。
- 业务操作时,避免对主键的修改。
4.3 排序优化
排序 order by可能会在解析执行计划中的Extra字段中显示:Using filesort。尽量在该字段中显示 Using index 或 back index scan这两种效率相对较高。
排序 order by,在Extra中可能出现的信息:
- Using filesort:通过表的索引或者全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序都叫FileSort排序。
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为Using index。 不需要额外排序,操作效率高。
- back index scan:索引的逆序扫描。
排序优化策略:
- 根据字段建立合适的索引(一般多为联合索引),多个写字段排序时,也要遵循最左前缀法则,所有顺序必须一一对应。
- 尽量使用覆盖索引。
- 在多个字段进行排序时,此时需要注意联合索引在创建时的规则(ASC/DESC),创建索引时就需要指明字段的索引顺序。
- 如果不可避免出现filesort,大数据量排序时,可以适当增加排序缓冲区大小sort_buffer_size(默认256K),查看缓冲区大小:
show variables like 'sort_buffer_size';
4.4 分组优化
分组 group by可能会在解析执行计划中的Extra字段中显示:Using temporary。尽量在该字段中显示 Using index 这种效率相对较高。
分组 group by,在Extra中可能出现的信息:
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为Using index。 不需要额外排序,操作效率高。
- Using temporary:使用临时表,效率比较低。
分组优化策略:
- 在分组操作时,可以通过索引来提高效率。
- 在分组操作时,也需要满足最左前缀法则。最左边的条件也可以是在where之后
4.5 分页优化
分页 limit时,如果在数据量的前提下,会出现深翻页的现象,导致查询时间过长。
分页优化思路:一般分页查询时,通过创建覆盖索引能够比较好的提高性能,可以通过覆盖索引加子查询形式进行优化。
4.6 总行数优化
求取数据库表中当前总记录行,在InnoDB存储引擎和MyISAM存储引擎中的差异:
- InnoDB存储引擎:没有单独记录在磁盘中,因此,查询数据库表中当前总记录行数时,需要把数据一行一行的从存储引擎里面读取出来,然后累计计数。
- MyISAM存储引擎:会把一个表的总行数存在了磁盘上,因此,查询数据库表中当前记录行数时,会直接返回该存储值,效率很高。
总行数优化思路:自己进行计数。
在InnoDB存储引擎中,聚合函数 count(),对于返回的结果集,一行一行判断,如果其参数不为NULL,累计值就加1,否则不加,最终返回累计值。
在InnoDB存储引擎中,聚合函数 count()的具体形式: count(*)、 count(主键)、 count(字段)、 count(1)。
count(主键):InnoDB引擎会遍历整张表,把每一行的主键ID值都取出来,返回给服务层,服务层拿到主键后,直接进行累加(主键不可能为null)。count(字段):- 没有NOT NULL约束:InnoDB引擎会遍历整张表,把每一行的字段值都取出来,返回给服务层,服务层判断是否为NULL,不为NULL,计数累加。
- 存在NOT NULL约束:InnoDB引擎会遍历整张表,把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count(1):InnoDB存储引擎会遍历整张表,但不取值,服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。count(*):InnoDB存储引擎不会把字段取出来,而是做了专门的优化,不取值,服务层直接进行累加。
在InnoDB存储引擎中,聚合函数 count()具体形式之间的效率关系:count(字段) < count(主键) < count(1) ≈ count(*),所以,在没有特殊要求下,尽量使用 count(*)。
4.7 更新优化
在InnoDB存储引擎中,为了避免锁从行级锁升级为表级锁,尽量在更新 update的条件上加入对应的索引。
在InnoDB存储引擎中,行锁是针对索引加的锁,而不是针对于记录加的锁,并且该索引不能失效,否则将会从行级锁升级为表级锁。
5. 视图/存储过程/触发器
5.1 视图
视图(view)是一种虚拟存在的表。视图中的数据在数据库中实际存在,行和列数据来定义查询中使用的表,并且是在生成视图时动态生成的。
视图(view)只保存了查询的SQL逻辑,不保存查询结果。所以,在创建视图时,主要是在创建这条DQL语句。
视图(view)的系列操作:
创建视图:
create [or replace] view 视图名称[(列名列表)] as select语句 [with [cascaded|local] check option]
查看视图:
-- 查看创建视图语句
show create view 视图名称;
-- 查看视图数据
select * from 视图名称...;
修改视图:
-- 通过create or replace 进行修改
create [or replace] view 视图名称[(列名列表)] as select语句 [with [cascaded|local] check option]
-- 通过alter进行修改
alter view 视图名称[(列名列表)] as select语句 [with [cascaded|local] check option]
删除视图:
drop view [if exists] 视图名称 [,视图名称]...;
视图中的检查选项 with [cascaded|local] check option:
当在创建视图使用检查选项后,该视图在进行插入、 更新、 删除操作时,都会对其进行校验,使其符合视图的定义。
视图的创建可以基于另一个视图,为了保持视图间的一致性,会检查视图之间的依赖规则。所以,cascaded 和 local 是会在视图间进行传递。
检查选项有:cascaded 和 local,默认值为:cascaded。
cascaded:创建视图时设置了with check option或者with cascaded check option检查选项,那么在插入数据时,需要判断当前视图的条件外,还需要判断引用视图的条件是否满足,直到引用的是基表为止;满足个条件后才可插入,反之抛出异常。local:创建视图时设置了with local check option检查选项,那么在插入数据时,需要判断该视图的条件,之后判断引用的视图是否存在检查选项,如果有则继续判断,反之不进行判断;满足各条件后才可插入,反之抛出异常。
视图中的数据是可以更新的,前提是视图中的行于基本表中的行之间必须是一对一的关系。
创建视图时,如果包含以下任意一项,则视图是不可更新:
- 聚合函数或者窗口函数(
sum()、min()、max()、count()等) 。 - 去重
distinct。 - 分组
group by。 - 筛选
having。 - 联合查询
union或union all。
使用视图的优点:
- 简单:视图不仅可以简化对数据的理解,也可以简化操作。可以将经常使用的查询定义为视图,从而避免以后每次操作指定全部的条件。
- 安全:数据库可以授权,但不能授权到数据库特定行和特定列上,通过视图只能查询和修改他们所能见到的数据。
- 数据独立:视图可以帮助用户屏蔽真实表结构带来的影响。
5.2 存储过程
存储过程是指事先经过编译并且存储在数据库中的一段SQL语句的集合。调用存储过程可以简化开发人员的工作,减少数据在数据库和应用服务器之间的传输,可提高数据库处理的效率。
存储过程的思想就是数据库SQL语言层面代码的封装和重用。
存储过程的特点:
- 封装和复用。
- 可以接收参数,也可以返回数据。
- 减少网络交互,提升效率。
存储过程的系列操作:
由于数据库管理工具会自动区分语句结束符和存储过程结束,如果在MySQL命令行中可以通过
delimiter进行指定语句的结束符号。示例:delimiter $$,以$$进行语句结尾。
创建存储过程:
create procedure 存储过程名称([参数列表])
begin
-- SQL语句
end;
调用存储过程:
call 名称([参数]);
查看存储过程:
-- 查询指定数据库的存储过程以及状态信息
select * from information_schema_routines where routines_schema = 'XXX'
-- 查询某个存储过程的定义
show create procedure 存储过程名称;
删除存储过程:
drop procedure [if exists] 存储过程名称;
存储过程变量:
存储过程的变量分为:系统变量、 用户自定义变量、 局部变量。
系统变量是MySQL服务器提供的,不是由用户自定义的。属于系统服务器层面,可以分为:全局变量(global)和会话变量(session)。
系统变量的系列操作:
如果没有指定session/global,默认情况是session(会话变量)。
查看系统变量及对应值:
-- 查看所有系统变量
show [session|global] variables;
-- 通过like模糊匹配方式查找变量
show [session|global] variables like '...';
-- 查看指定变量的值
select @@[session|global.] 系统变量名;
设置系统变量的值:
-- 方式一
set [session|global] 系统变量名 = 值;
-- 方式二
set @@[session|global] 系统变量名 = 值;
MySQL服务器重启后,所有设置的全局参数会失效。如若不想重启失效,可以在配置文件my.cnf中配置。
用户自定义变量是用户需要自己手动定义的变量,用户不用提前声明,在使用时直接**@变量名使用就可以。用户自定义变量的作用域为当前连接的客户端**。
用户自定义变量系列操作:
用户自定义变量无需对其进行声明或初始化。如果未定义,获取到的值为NULL。
创建用户自定义变量并赋值:
-- 方式一:通过set赋值
set @var_name = expr [,@var_name = expr]...;
set @var_name := expr [,@var_name := expr]...;
-- 方式二:通过select赋值
select @var_name := expr [,@var_name := expr]...;
select 字段名 into @var_name from 表名;
使用用户自定义变量:
select @var_name;
局部变量是根据需要定义的局部生效的变量,访问之前需要通过 declare声明。作用于存储过程内部的局部变量和输入参数,局部变量的范围是在其内声明的 begin...end块中。
局部变量的系列操作:
声明局部变量:
-- 变量类型就是数据库字段类型: INT、 BIGINT、 CHAR、 VARCHAR、 DATE、 TIME等
declare 变量名 变量类型 [defalut ...];
赋值局部变量:
set 变量名 = 值;
set 变量名 := 值;
select 字段名 into 变量名 from 表名...;
存储过程语法:
传入参数:变量 变量名 变量名类型,变量名类型有三种:IN、OUT、INOUT。
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类型作为输入,也就需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 既可以作为输入参数,也可以作为输出参数 |
IF 语法块:
if 条件1 then
...
elseif 条件2 then -- 可选
...
else -- 可选
...
end if;
CASE 语法块:
-- 方式一
case case_value
when when_value1 then statement_list1
[when when_value2 then statement_list2]...
[else statement_list]
end case;
-- 方式二
case
when search_condition1 then statement_list1
[when search_condition2 then statement_list2]...
[else statement_list]
end case;
WHILE 语法块:满足条件后,再执行循环体中的SQL语句。
-- 先判定条件,如果条件为true,则执行逻辑,否则,不执行逻辑
while 条件 do
SQL逻辑...
end while;
REPEAT 语法块:当满足条件时退出循环。
-- 先执行一次逻辑,然后判定逻辑是否满足,如果满足,则退出。如果不满足,则继续下一次循环
repeat
SQL逻辑...
until 条件
end repeat
LOOP 语法块:如果不在LOOP中添加退出循环条件,即可变成死循环。配合使用的两个语句:leave 和 iterate。
leave: 配合循环使用,退出循环。iterate: 必须在循环中,跳过当前循环的后续语句,直接进入到下一次循环。
-- loop语法块
[begin_label:]loop
SQL逻辑...
end loop[end_label];
-- leave 和 iterate 的使用
leave label; -- 退出指定标记的循环体
iterate label; -- 直接进入下一次循环
CURSOR 语法块:游标是用来存储查找结果集的数据类型,在存储过程和函数中可以使用右表对结果集进行循环处理,游标的使用包括:声明游标、打开游标、遍历游标记录、关闭游标。
-- 声明游标
delcare 游标名称 cursor for 查询语句;
-- 打开游标
open 游标名称;
-- 遍历游标记录
fetch 游标名称 into 变量 [,变量]...;
-- 关闭游标
close 游标名称;
条件处理程序: 条件处理程序(handler)可以用来定义流程控制结构执行中遇到问题时相应的处理步骤,一般配合游标cursor一起使用。
-- handler 声明
declear handler_action handler for condition_value[,condition_value]... statement;
-- handler_action 参数
continue -- 继续执行当前程序
exit -- 终止执行当前程序
-- condition_value参数
sqlstate sqlstate_value :状态码,如02000
sqlwarning :所有以01开头的sqlstate代码的简写
not found :所有以02开头的sqlstate代码的简写
sqlexception :所有没有被sqlwarning或not found捕获的sqlstate代码的简写
5.3 存储函数
存储函数有返回值的存储过程,存储函数中的传入参数只能是 IN类型的。
create function 存储函数名称([参数列表])
returns type [characteristic...]
begin
--SQL语句
return ...;
end;
-- characteristic说明:
deterministic :相同的输入参数总是产生相同的结果
no sql :不包含SQL语句
reads sql data :包含读取数据的语句,但不包含写入数据的语句
5.4 触发器
触发器是与数据库表有关的数据库对象。在数据库表进行 insert、update 和 delete 之前或之后,触发并执行触发器中已经预先定义好的SQL语句的集合。触发器主要是协助应用在数据库端确保数据的完整性。应用场景为日志记录,数据校验等操作。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他数据库是类似的。目前触发器还只支持行级触发、不支持列级和语句级别触发。
| 触发器类型 | NEW和OLD |
|---|---|
| INSERT型触发器 | NEW表示将要或者已经新增的数据 |
| UPDATE型触发器 | OLD表示修改之前的数据,NEW表示将要或已经修改后的数据 |
| DELETE型触发器 | OLD表示将要或者已经删除的数据 |
触发器的系列操作:
创建触发器:
create trigger trigger_name
before/after insert/update/delete
on 表名 for each row -- 行级触发器
begin
trigger_statement;
end;
查看触发器:
show trigger;
删除触发器:
-- 如果没有指定schema_name,默认为当前数据库
drop trigger [schema_name] trigger_name;
6. 锁
锁是计算机通过协调进程或线程并发访问某一资源的机制。在数据库中,除了传统的计算资源(CPU、 RAM、 I/O)的争用外,数据也是一种提供许多用户共享的资源。存在锁的原因是要保障数据并发访问的一致性、有效性。锁冲突也会影响数据库并发访问性能的一个重要因素。因此,锁对数据而言极其重要,也更加复杂。
数据库的锁按照粒度分类:
- 全局锁:锁定数据库中的所有表。
- 表级锁:每次操作锁住整张表。
- 行级锁:每次操作锁住对应的行数据。
6.1 全局锁
全局锁是对于整个数据库实例加锁,加锁后整个实例就处于只读状态,后续的DML语句和DDL语句都将被阻塞。
经典场景就是在做全库的逻辑备份,对所有表进行锁定,从而获取一致性视图,保证数据的完整性。
数据库中加全局锁,是一个比较中的操作。
全局锁的执行过程:
-- 进入数据库中加锁
flush tables with read lock;
-- 在命令终端中执行全局备份
mysqldump -u 用户名 -p 数据库名 > 备份路径/备份名称.sql
-- 进入数据库中释放锁
unlook tables;
全局锁的特点:
- 如果是在主库中进行备份,那么备份期间都不能执行更新操作,业务基本处于停滞状态。
- 如果是在从库上进行备份,那么备份期间从库不能执行主库同步过来的二进制日志(binlog),会导致主从数据延迟。
在InnoDB引擎中,我们在备份时可以加入参数 --single-transaction 参数来完成不用全局锁的一致性数据备份。
-- 执行全局备份:底层快照读方式
mysqldump --single-transaction -u 用户名 -p 密码 数据库名 > 备份路径/备份名称.sql
7.2 表级锁
表级锁在每次操作会锁住整张表,锁定粒度大,发生锁冲突的概率最高,并发度低。应用在MyISAM、 InnoDB、 BDB(Berkeley DB)等存储引擎中。
表级锁分为三类:表锁、元数据、意向锁。
表锁:
表锁分为两类:表共享读锁(read lock)和表独占写锁(write lock)。
表锁的操作:
-- 进入数据库中,对表加锁
lock tables 表名... read/write
-- 进入数据库中,对表释放锁(两种方式)
unlock tables / 断开客户端连接
元数据锁:(meta data lock,MDL)
MDL加锁过程是系统自动控制,无需显式使用。在访问一张表的时候会自动加上。MDL锁的作用主要是为了维护表元素数据的一致性,在表上有活动事务的时候,不可以对元数据进行写入操作,以避免DML与DDL冲突,从而保证读写的正确性。
MDL是在MySQL5.5中引入,当对一张数据库表进行增删改查时,加入元数据读锁(共享);当对表结构进行变更操作的时候,加入元数据写锁(排他)。
| 对应SQL | 锁类型 | 说明 |
|---|---|---|
| lock tables XXX read/write | shared_read_only / shared_no_read_write | |
| select、selec…lock in share mode | shared_read | 与shared_read、shared_write兼容,与exclusive互斥 |
| insert、update、delete、select…for update | shared_write | 与shared_read、shared_write兼容,与exclusive互斥 |
| alter table… | exclusive | 与其他的MDL都互斥 |
查看元数据锁:
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
意向锁:
为了避免DML在执行时,加的行锁于表锁发生冲突。在InnoDB存储引擎中加入了意向锁,使表锁不用检查每一行数据都是否加锁,从而减少表锁的检查。
意向锁的分类:
- 意向共享锁(IS):由语句
select...lock in share mode添加。 - 意向排他锁(IX):由
insert、 update、 delete、 select...for update添加。
意向锁的兼容情况:
- 意向共享锁(IS):与表锁共享锁(read)兼容,与表锁排他锁(write)互斥。
- 意向排他锁(IX):与表锁共享锁(read)及排他锁(write)都互斥。意向锁之间不会互斥。
查看意向锁:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
7.3 行级锁
行级锁是在每次操作数据库表的对应行数据加上锁,锁的粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中。
InnoDB的数据时基于索引组织的,行锁是通过对索引上的索引项加锁实现的,而不是对记录加的锁。
行级锁分为三类:行锁、间隙锁、临键锁。
- 行锁(Record Lock):锁定单个记录的锁,防止其他事务对此行数据进行更新和删除操作。在RC和RR隔离级别下都支持。
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引间隙不变,防止其他事务在这个间隙进行插入操作,产生幻读。在RR隔离级别下支持。
- 临键锁(Next-Key Lock):行锁和间隙锁的结合。
行锁:
在InnDB存储引擎中,实现了以下两种类型的行锁:
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
共享锁和排他锁之间关系:
| 锁类型 | S(共享锁) | X(排他锁) |
|---|---|---|
| S(共享锁) | 兼容 | 冲突 |
| X(排他锁) | 冲突 | 冲突 |
行锁在SQL举例中分类:
| SQL | 行锁类型 | 说明 |
|---|---|---|
| insert… | 排他锁 | 自动加锁 |
| update… | 排他锁 | 自动加锁 |
| delete… | 排他锁 | 自动加锁 |
| select… | 不加任何锁 | |
| select…lock in share mode | 共享锁 | 需要手动在select之后加入,lock in share mode |
| select..for update | 排他锁 | 需要手动在select之后加入for update |
行锁和表锁之间的转化:
- 针对唯一索引进行检索时,对已存在的记录进行等值匹配时,会自动优化为行锁。
- InnoDB存储引擎的行锁时针对与索引加的锁,不通过索引条件检索数据,那么InnoDB存储引擎将表中所有记录加锁,此时就会升级为表锁。
查看行锁的加锁情况:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
间隙锁/临键锁:
在默认情况下,InnoDB存储引擎在RR事务隔离级别运行,使用Next-Key锁进行搜索和索引扫描,防止出现幻读。
间隙锁唯一目的就是防止其他事务插入间隙。间隙锁可以共存,一个事务采用的间隙锁,不会阻止另一个事务在同一个间隙上采用间隙锁。
间隙锁和临键锁使用场景:
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁。
- 索引上的等值查询(普通索引),向右遍历时最后一个值不满足查询需求时,临键锁退化为间隙锁。
- 索引上的范围查询(唯一索引),会访问到不满足条件的第一个值为止,插入临键锁。
8. InnoDB核心
8.1 逻辑存储结构
InnoDB存储引擎的逻辑存储结构从大到小一次是:表空间(tablespace)-> 段(segment)-> 区(extend)-> 页(page)-> 行(row)。
- 表空间(tablespace):idb文件,在一个MySQL实例中可以对应多个表空间,用于存储记录、 索引等数据。
- 段(segment):分为数据段(leaf node segment)、索引段(Non-leaf node segment)、回滚段(Rollback segment),InnoDB存储引擎是索引组织表,数据段就是B+ tree的叶子节点,索引段就是B+ tree的非叶子节点。段用来管理多个区(Extent)。
- 区(Extent):表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16K,即一个区中一共有64个连续的页。
- 页(page):InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎会每次从磁盘申请4-5个区。
- 行(row):InnoDB存储引擎数据是按行进行存放的。Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。Roll_pointer:每次对某个记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
8.2 物理架构
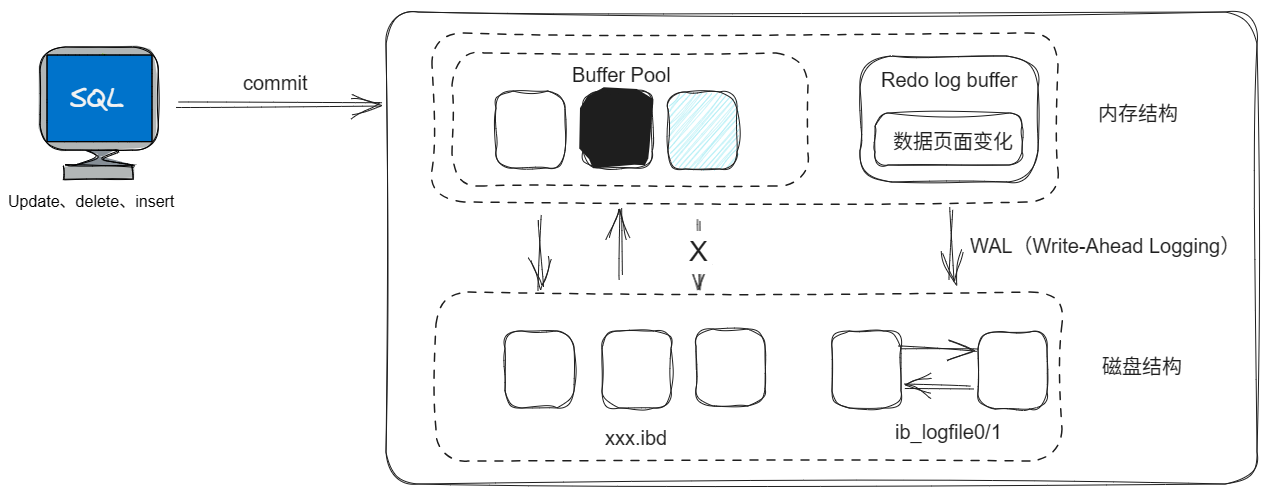
从MySQL5.5版本开始,默认使用的是InnoDB存储引擎,他擅长处理事务,具有崩溃恢复特征,在日常开发中使用也是非常广泛。

上图为InnoDB存储引擎的物理架构图,左侧为内存结构,右侧为磁盘结构。
内存结构:
Buffer Pool:缓冲池是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘中,从而减少磁盘IO,加快处理速度。
缓冲池以page页为单位,底层采用链表数据结构管理page。根据状态,将page分为三种类型:
- free page:空闲page,未被使用。
- clean page:被使用page,数据没有被修改过。
- dirty page:脏页,被使用page,数据被修改过,页中数据与磁盘的数据产生了不一致。
change buffer:更改缓冲区,在MySQL8.0之后引入,在MySQL5.X版本为Insert Buffer,针对于非一二级索引页,在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区中,Change Buffer中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
Change Buffer引入的意义:与聚集索引不同,二级索引通常是非唯一的,并且以相对于随机的顺序插入二级索引。同样,删除和更新可能会影响索引中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了Change Buffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
Adaptive Hash Index:自适应Hash索引,用于优化对Buffer Pool数据的查询。InnoDB存储引擎会监控对表上各索引页的查询,如果观察到Hash索引可以提升速度,则建立hash索引,称之为自适应hash索引。
自适应哈希索引,无需人工干预,是系统根据情况自动完成。
自适应Hash索引参数:adaptive_hash_index。
Log Buffer:日志缓冲区,用来柏村要写入到磁盘中的log日志数据(redo log、undo log),默认大小为16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或者删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
日志缓冲区的参数:
innodb_log_buffer_size:缓冲区大小innodb_flush_log_at_trx_commit:日志刷新到磁盘时机;
1 -> 日志在每次事务提交时写入并刷新到磁盘
0 -> 每秒将日志写入并刷新到磁盘一次
2 -> 日志在每次事务提交后写入,并每秒刷新到磁盘一次
磁盘结构:
System Tablespace(ibdata1):系统表空间是更改缓冲区的存储区域,如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)。
系统表空间的参数:innodb_data_file_path。
File-Per-Table Tablespaces:每个表的文件空间包含单个InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。
每个文件单独表空间参数:innodb_file_per_table。
General Tablespaces:通用表空间,需要通过create tablespace语法创建通用表空间,在创建表时,可以指定该表空间。
通用表空间的系列操作:
-- 创建表空间
create tablespace 表空间名称 add datafile '表空间名称' engine=存储引擎;
-- 使用该表空间
create table 数据库表名称(字段名 字段属性...) tablespace 表空间名称;
Undo Tablespaces:撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储Undo log日志。
Temporary Tablespaces:InnoDB使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
Doublewrite Buffer Files:双写缓冲区,InnoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
Redo Log:重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者是在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中,用于刷新脏页到磁盘时,发生错误时,进行数据恢复使用。重做日志是循环写入日志文件。
后台线程:
后台线程工作是将数据定期从内存结构写入到磁盘结构。
Master Thread:核心后台线程,负责调度其它线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收。
IO Thread:在InnoDB存储引擎中大量使用了AIO来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。查看命令: show engine innodb status;
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read Thread | 4 | 负责读操作 |
| Write Thread | 4 | 负责写操作 |
| Log Thread | 1 | 负责将日志缓冲区刷新到磁盘 |
| Insert Buffer Thread | 1 | 负责将写缓冲区内容刷新到磁盘 |
Purge Thread:主要用于回收事务已经提交了的Undo log,在事务提交之后,undo log可能不用了,就用它来进行回收。
Page Cleaner Thread:协助Master Thread刷新脏页到磁盘的线程,它可以减轻Master Thread的工作压力,减少阻塞。
8.3 事务原理
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务的四大特性:原子性、一致性、隔离性、持久性。
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的原子性、一致性、持久性,在MySQL的InnoDB存储引擎中依赖于 redo.log 和 undo.log 日志。
事务的隔离性,在MySQL的Innodb存储引擎中,依赖于 锁 和 MVCC。
redo log -> 持久性:重做日志,记录的是事务提交时数据页的物理修改,用来实现事务的持久性
redo log日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者是在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中,用于刷新脏页到磁盘,发生错误时,进行数据恢复使用。
undo log -> 原子性:回滚日志,用于记录数据被修改前的信息,作用包含两个:提供 回滚 和 MVCC(多版本并发控制)。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete 一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当Update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录中读取到对应内容并进行回滚。
undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
undo log存储:undo log采用段的方式进行管理和记录,存放在rollback segment回滚段中,内部包含1024个undo log segment中。
8.4 多版本并发控制
多版本并发控制(MVCC)全称 Multi-Version Concurrency Control。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还是需要依赖于数据库中的三个隐式字段、undo log日志、readView。
当前读: 读取的时记录的最新版本,读取时还要保证其它并发事务不能修改当前记录,会对读取的记录进行加锁。对于日常的操作,如:select...lock in share mode(共享锁), select...for update、update、insert、delete(排它锁)都是一种当前读。
快照读: 简单的select(不加锁)就是快照读。快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
快照读在读已提交、不可重复度和序列化的隔离级别的情况:
- Read Committed:每次select,都生成一个快照读。
- Repeatable Read:开始事务后第一个select语句才是快照读的地方。
- Serializable:快照读会退化为当前读。
MVCC的实现原理:
记录中的隐藏字段(DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID)
| 隐藏字段 | 含义 |
|---|---|
| DBTRXID | 最近修改事务ID,记录插入这条记录或者最后一次修改该记录的事务ID |
| DBROLLPTR | 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本 |
| DBROWID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段 |
undo log:回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志。
- 当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。
- 当update、delete的时候,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会立即被删除。
undo log版本链:DB_ROLL_PTR字段之间关联,不同事物或相同事物对同一条记录进行修改,会导致该记录的undo log生成一条记录版本链表,链表的头部是最新的旧纪录,链表尾部是最早的旧纪录
readView:ReadView(读视图)是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事物(未提交的)id。
ReadView中包含了四个核心字段:
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
ReadView版本链数据访问规则:(trx_id:代表当前数据行记录事务ID,与 DB_TRX_ID相同)
- trx_id == creator_trx_id -> 可以访问该版本,说明数据就是当前事务更改的
- trx_id < min_trx_id -> 可以访问该版本,说明数据已经提交了
- trx_id > max_trx_id -> 不可以访问该版本,事务在ReadView后才开启
- min_trx_id ≤ trx_id≤ max_trx_id -> 如果trx_id不在m_ids中是可以访问该版本的,说明数据已经提交
不同的隔离级别,生成的ReadView的时机不同:
- READ COMMITTED:在事务中每一次执行快照读时生成ReadView
- REPEATABLE READ:仅在事务中第一次执行快照读时生成ReadView,后续使用该ReadView
9. MySQL管理
9.1 系统数据库
MySQL数据库安装完成之后,自带了以下四个数据库: mysql、information_schema、performace_schema、sys。
| 数据库 | 含义 |
|---|---|
| mysql | 存储MySQL服务器正常运行所需要的各种信息(时区、主从、用户、权限等) |
| information_schema | 提供了访问数据库元数据的各种表和视图,包含数据库、表、字段类型及访问权限等 |
| performace_schema | 为MySQL数据库运行时提供了一个底层监控功能,主要用于收集数据库服务器性能参数 |
| sys | 包含了一系列方便DBA和开发人员利用performance_schema性能数据库进行调优和诊断的视图 |
9.2 常用命令工具
mysql:
-e 选项可以在MySQL客户端执行SQL语句,而不用连接到MySQL数据库在执行,对于一些批处理脚本,这种方式尤其方便
mysql -u用户名 -p数据库密码 数据库名 -e "sql语句";
mysqladmin:
mysqladmin是一个执行管理操作的客户端程序。可以用它来检查服务器的配置和当前状态、创建并删除数据库等。
mysqlbinlog:
由于服务器生成的二进制日志文件以二进制格式保存,如果想要检查这些文本的文本格式,就会使用到mysqlbinlog日志管理工具。
mysqlbinlog [options] log-files1 log-files2...
mysqlshow:
mysqlshow客户端对象查找工具,用来很快地查找存在哪些数据库、数据库中的表、表中的列或索引。
mysqlshow [options] [db_name|table_name|col_name]
options:
--count 显示数据库及表的统计信息(数据库、表均可以不指定)
-i 显示指定数据库或者指定表的状态信息
查询每个数据库的表的数据及表中记录的数据量
mysqlshow -u用户名 -p密码 --count
查询test库中每个表中的字段数及行数
mysqlshow -u用户名 -p密码 test --count
查询test数据库中demo表的详细情况
mysqlshow -u用户名 -p密码 test demo --count
mysqldump:
mysqldump客户端工具用来备份数据库或在不同数据库之间进行数据迁移。备份内容包含创建表,及插入表的SQL语句。
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
mysqlimport/source:
mysqlimport是客户端数据导入工具,用来导入mysqldump加 -T 参数后导出的文本文件
mysqlimport [options] db_name textfile1 [textfile2...]
如果需要导入sql文件,可以使用mysql中的source指令:需要在mysql中执行
source xxx.sql文件路径
运维篇
1. 日志
1.1 错误日志
错误日志是MySQL中最重要的日志之一。它记录了当mysqld重启和停止,以及服务器在运行过程中发生的任何严重错误时的相关信息。当数据库出现了任何故障导致无法正常使用时,建议首选查看错误日志信息。
错误日志默认时开启的,默认存放路径/var/log/,默认的日志文件名为 mysqld.log。
通过MySQL命令查看错误日志位置:
show variables like '%log_error%';
1.2 二进制日志
二进制日志(binlog)记录了所有的DDL和DML语句,但不包括数据库查询语句。在MySQL8.x版本中,默认二进制日志是开启的。
二进制日志的作用: 1. 灾难时的数据恢复。 2. MySQL的主从复制。
通过MySQL命令查看二进制日志位置:
show variables like '%log_bin%';
二进制日志格式包含:STATEMENT、ROW、MIXED 三种。
| 日志格式 | 含义 |
|---|---|
| STATEMENT | 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中 |
| ROW | 基于行的日志记录,记录的是每一行的数据变更。(默认) |
| MIXED | 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下自动切换为ROW进行记录 |
通过MySQL命令查看当前二进制日志文件格式:
show variables like '%binlog_format%';
修改二进制文件格式,通过my.cnf配置文件修改,文件中添加或调整binlog_formate=二进制日志格式,然后重新启动MySQL数据库。
二进制日志删除:对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不删除,将会占用大量磁盘空间。
二进制日志文件,通过以下三种集中方式清理日志:
| 指令 | 含义 |
|---|---|
| reset master | 删除全部binlog日志,删除之后,日志编号,将从binlog.000001重新开始 |
| purge master logs to 'binlog.******' | 删除******编号之前的所有日志 |
| purge master logs before 'yyyy-mm-dd hh24:mi:ss' | 删除日志为“yyyy-mm-dd hh24:mi:ss”之前产生的所有日志 |
二进制日志文件,也可以在MySQL配置文件中配置过期时间(binlog_expire_logs_seconds),进行过期自动删除。
查看二进制文件过期时间(默认:2592000s,30天):
show variables like '%binlog_expire%'
1.3 查询日志
查询日志中记录了客户端的所有操作日志。默认情况下,查询日志是未开启的。
通过MySQL命令查看查询日志是否开启:
show variables like '%general%';
开启查询日志,通过my.cnf配置文件修改,文件中添加或调整general_log和general_log_file两个参数,然后重新启动MySQL数据库。
# 该选项用来开启查询日志,可选值:0或者1;0 代表关闭,1 代表开启
general_log=1
# 设置日志的文件名,如果没有指定,默认的文件名为host_name.log
general_log_file=文件名.log的绝对路径
1.4 慢查询日志
慢查询日志记录了所有执行时间超过预设时间(long_query_time)和扫描记录数不小于最小测试行限制(min_examined_row_limit)的SQL语句。慢查询日志默认是未开启的。
预设时间,参数: long_query_time 默认是10s,最小为0s,精度可以到微妙。
开启慢查询日志,通过my.cnf配置文件修改,文件中添加或调整slow_query_log和long_query_time两个参数,然后重新启动MySQL数据库。
# 慢查询日志
slow_query_log=1
# 执行时间参数,默认单位:秒
long_query_time=2
在默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询语句。为了记录超时的管理语句和不使用索引进行查找的查询语句,通过my.cnf配置文件修改,文件中添加或调整log_slow_admin_statement和log_queries_not_using_indexs两个参数。
# 记录执行比较慢的管理语句
log_slow_admin_statements=1
# 记录执行较慢的未使用索引的语句
log_queries_not_using_indexes=1
2. 主从复制
主从复制是指将煮数据库的DDL和DML操作通过二进制日志传到从服务器中,然后在从库中对这些日志重新执行(重做),从而使得从库和主库的数据保持同步。
MySQL数据库支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL的主库称为master;MySQL的从库称为slave。
MySQL数据库的主从复制主要包含以下三个方面:
- 主库出现问题,可以快速切换到从库提供服务。
- 实现读写分离,降低主库的访问压力。
- 可以在从库中执行备份,避免备份期间影响主库服务。(该备份可能存在数据延迟)
2.1 原理
主从复制的原理图如下:
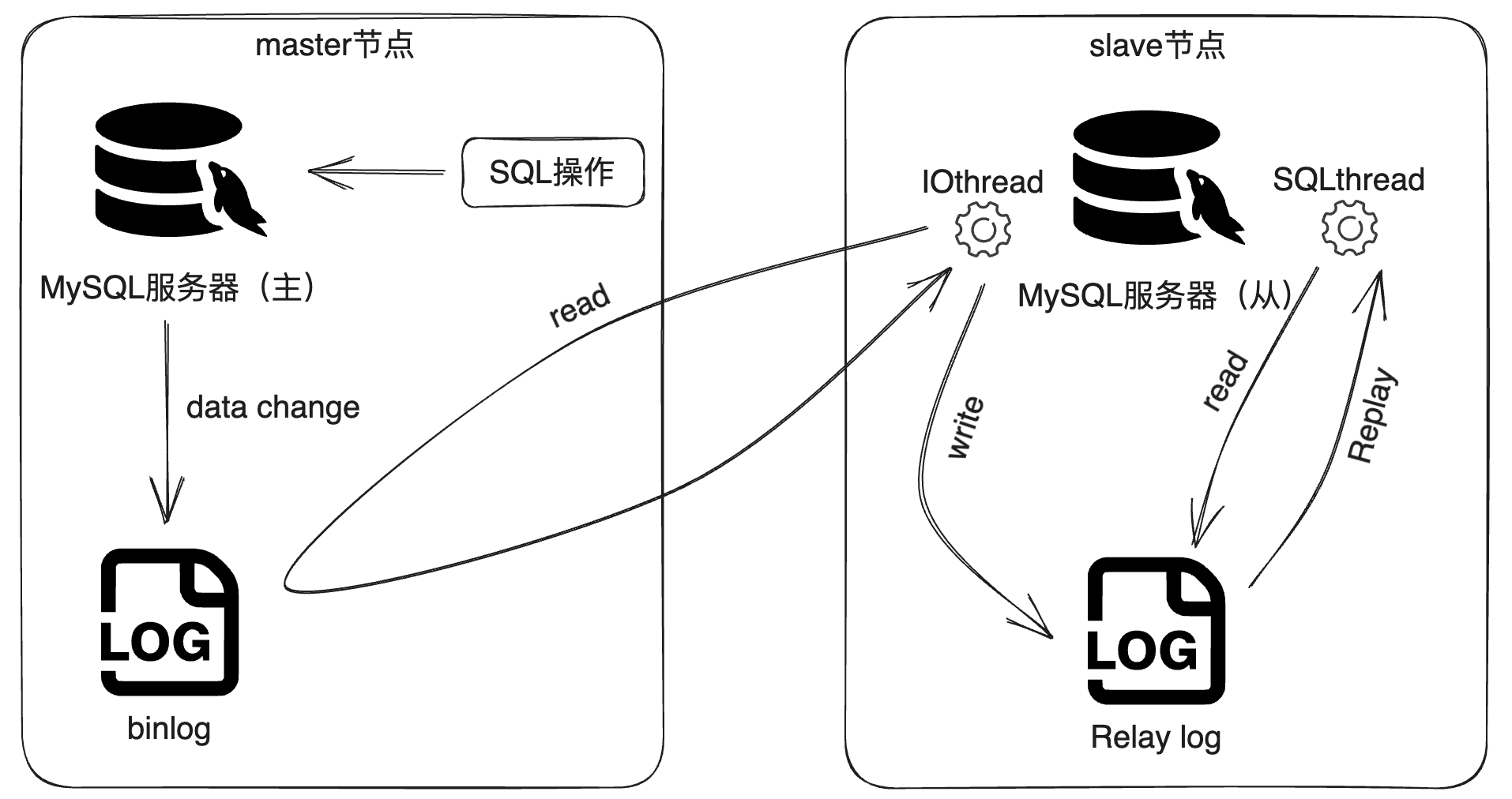
主从复制的原理主要分为三步:
- master主库在事务中提交时,会把数据变更记录在二进制日志文件binlog中。
- 从库读取主库的二进制文件binlog,写入到从库的中继日志relay log中。
- slave从库重做中继日志中的事件,将改变反映到它自己的数据库中。
2.2 搭建
服务器准备:
步骤1:master和slave节点,开放指定的3306端口或关闭服务器的防火墙
# 开放指定的3306端口
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --reload
# 关闭服务器的防火墙 一般不建议直接关闭服务器防火墙
systemctl stop firewalld
systemctl disable firewalld
步骤2:master和slave节点服务器安装MySQL数据库
Linux系统安装过程可参照进阶篇的第二节: Linux安装MySQL
主库配置(master):
步骤1:修改my.cnf配置文件
# mysql 服务ID,保证整个集群环境中唯一,取值范围:1 - 2^32-1。默认为1
server-id=1
# 是否只读,1 代表只读,0 代表读写
read-only=0
# 忽略的数据,指不需要同步的数据库
#binlog-ignore-db=mysql
# 指定同步的数据库
#binlog-do-db=db01
步骤2:重启数据库
systemctl restart mysqld
步骤3:登陆MySQL,创建远程连接的账号,并授予主从复制的权限
-- 创建replicauser,并设置密码,该用户可以在任意主机连接该MySQL服务
create user 'replicauser'@'%' identified with mysql_native_password by 'Root@123456';
-- 为 'replicauser'@'%' 用户分配主从复制权限
grant replication slave on *.* to 'replicauser'@'%';
步骤4:通过MySQL命令查看当前二进制日志的文件名和坐标
show master status;
status查询的结果部分字段含义说明:
- file:从哪个日志文件开始推送日志文件。
- position:从哪个位置开始推送日志。
- binlog_ignore_db:指定不需要同步的数据库。
从库配置:
步骤1:修改my.cnf配置文件
# mysql 服务ID,保证整个集群环境中唯一,取值范围:1 - 2^32-1。默认为1
server-id=2
# 是否只读,1 代表只读,0 代表读写
read-only=1
# 设置超级管理员也是只读的
#super-read-only=1
步骤2:重启数据库
systemctl restart mysqld
步骤3:登陆MySQL,设置与主库建立连接
change replication source to source_host='xxx.xxx.xxx.xxx',source_user='replicauser',source_password='Root@123456',source_log_file='binlog.xxxxxx',source_log_pos=位置;
-- 在8.0.23之前版本:
change master to master_host='xxx.xxx.xxx.xxx',master_user='replicauser',master_password='Root@123456',master_log_file='binlog.xxxxxx',master_log_pos=位置;
步骤4:开启与主库同步的开关
start replica;
-- 在8.0.22之前
start slave;
步骤5:查看与主库同步的状态信息
show replica status;
-- 在8.0.22之前
show slave status;
关注字段:Replica_IO_Running 和 Replica_SQL_Running 均为 YES,标志主从复制开启正常。
至此,搭建主从复制完成。
3. 分库分表
随着互联网和移动互联网的发展,应用系统的数据量也是在呈现指数式增长。如若采用单数据库进行存储,就会存在以下瓶颈:
- IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。请求数据太多,带宽不够,网络IO瓶颈。
- CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
分库分表的思想是数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提高数据库性能的目的。
分库分表的拆分策略:
- 垂直拆分:垂直分库和垂直分表
- 水平拆分:水平分库和水平分表
垂直拆分 -> 垂直分库:以表为依据,根据业务不同将表拆分到不同的库中。
垂直分库的特点:
- 每个数据库的表结构都不一样。
- 每个数据库的数据也不一样。
- 所有数据库的并集是全量数据。
垂直拆分 -> 垂直分表:以字段为依据,根据字段的属性将不同字段拆分到不同表中。
垂直分表的特点:
- 每个数据库表的结构都不一样。
- 每个数据库表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有的数据库表的并集是全量数据。
水平拆分 -> 水平分库:以字段为依据,按照一定的策略,将一个数据库的数据拆分到多个库中。
水平分库的特点:
- 每个数据库的表结构都一样。
- 每个数据库的数据都不一样。
- 所有数据库的并集是全量数据。
水平拆分 -> 水平分表:以字段为依据,按照一定的策略,将一个库的数据拆分到多个库中。
水平分表的特点:
- 每个数据库表的表结构都一样。
- 每个数据库表的数据都不一样。
- 所有数据库表的并集是全量数据。
分库分表的拆分对象:1. 数据库;2. 数据库表。
分库分表的实现技术:
- shardingJDBC: 基于AOP原理,在应用程序对本地执行的SQL进行拦截、 解析、 改写、 路由处理。需要自行编码配置实现,只支持java语言,性能较高。
- MyCat: 数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
3.1 MyCat介绍
MyCat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用MySQL一样来使用MyCat,对于开发人员来讲是数据无感知切换。
MyCat的优势:
- 性能可高稳定。
- 强大的技术团队。
- 体系完善。
- 社区活跃。
MyCat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运行环境。
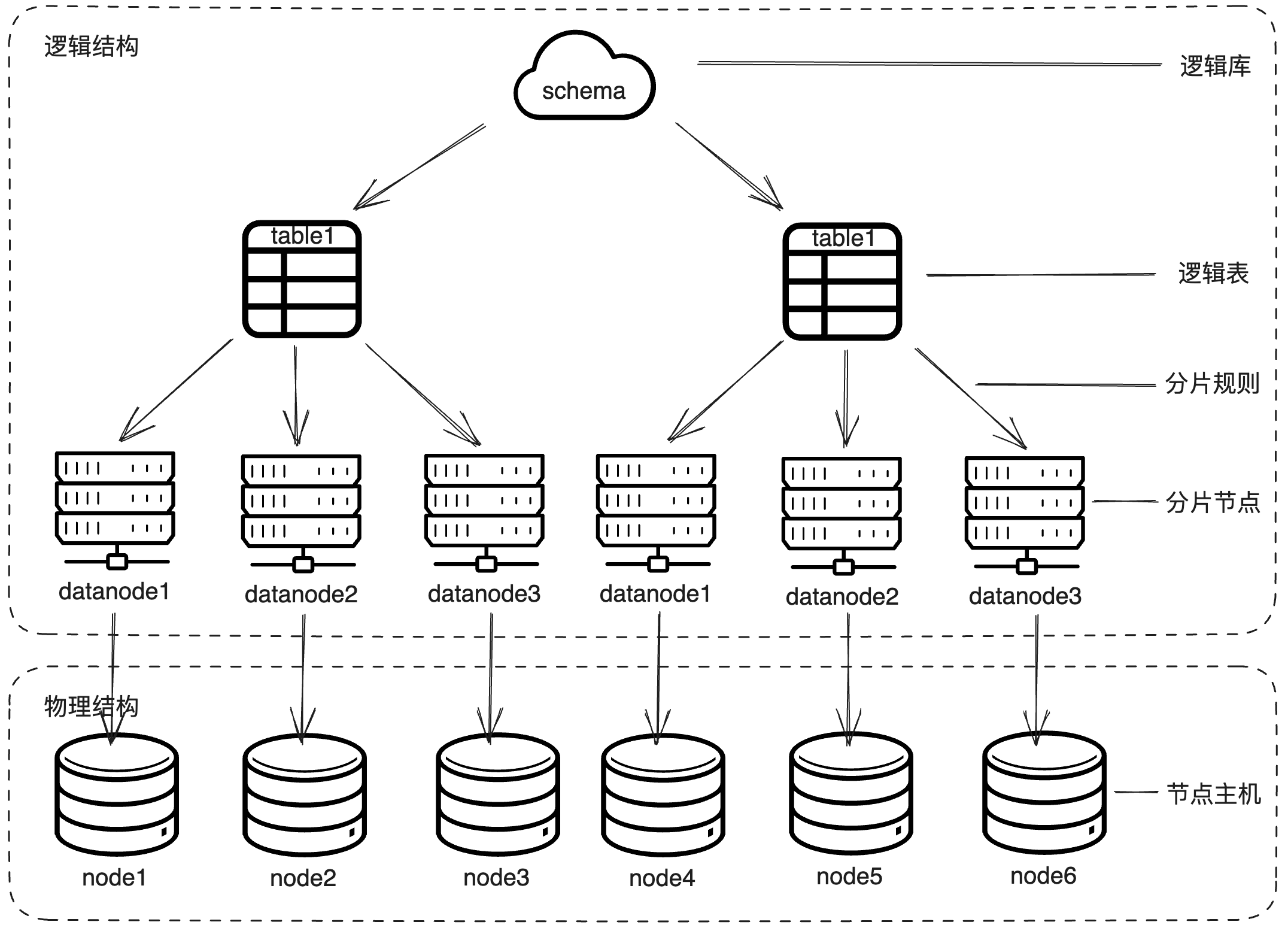
MyCat的概念图:通过MyCat的逻辑结构,映射到对应实际的物理结构。
3.2 MyCat安装
MyCat下载地址:http://www.mycat.org.cn/
MyCat依赖的环境:JDK和MySQL。
MyCat下载完成之后,解压即可使用,如果MySQL数据库的版本是8.x的话,需要更新MyCat的lib目录中MySQL的JDBC连接驱动包。
MyCat的目录结构说明:
- bin:存放可执行文件,用于启动停止MyCat。
- catlet:多表联查时涉及目录。
- conf:存放MyCat的配置文件。
- lib:存放MyCat的项目依赖包(jar包)。
- logs:存放MyCat的日志文件。
MyCat启停命令:进入MyCat的bin目录下
# 启动
mycat start
# 停止
mycat stop
MyCat连接测试:
# 用户名和密码在server.xml中配置
mysql -h mycat的ip地址 -p 8066 -uroot -p123456
3.3 MyCat配置文件
MyCat配置主要集中在三个配置文件中:1.schema.xml;2.rule.xml;3.server.xml。
schema.xml配置文件:
schema.xml中配置了逻辑库、逻辑表、分片规则、分片节点及数据源。聚焦标签于:1.schema标签;2.datanode标签;3.datahost标签。
schema标签用来定义MyCat实例中的逻辑库,一个MyCat实例中,可以有多个逻辑库,可以通过该标签来划分不同的逻辑库。
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="travelrecord,address" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>
</schema>
schema标签等同于MySQL数据库的database的概念,需要操作某个逻辑库下的表时,也需要先切换到对应的逻辑库(use xxx)。
schema核心属性:
- name:用于自定义的逻辑库名
- checkSQLschema:SQL语句操作时指定了数据库名,在执行时是否自动去除;true:自动去除指定的数据库名。
- sqlMaxLimit:如果位置定limit进行查询,列表查询默认查询的记录数。
datanode标签用来定义MyCat中的数据节点,也就是数据分片。一个datanode标签就是一个独立的数据分片。
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
datahost标签用来定义MyCat的物理数据库。直接定义具体的数据库实例、读写分离、心跳语句。
datahost核心属性:
- name:唯一标识,供datanode的dataHost属性使用。
- maxCon/minCon:最大连接数/最小连接数。
- balance:负载均衡策略,取值: 0、 1、 2、 3。
- writeType:写操作分发方式(0: 写操作转发到第一个writeHost标签,如果第一个挂了,再切换到第二个; 1: 写操作随机分法到配置的writeHost标签上)。
- dbDriver:数据库驱动,支持native和jdbc两种。(MySQL8.x对native的支持不是很好,一般选择jdbc驱动)。
rule.xml配置文件:
rule.xml中定义了所有拆分表的规则,使用过程中可以灵活的使用其预置好的分片算法,或者对同一个分片算法使用不同的参数,让分片过程可配置话。聚焦标签于: 1. tableRule标签; 2. Function标签。
tableRule标签主要指定分片的字段列和算法名称。其样例格式如下:
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-date">
<rule>
<columns>createTime</columns>
<algorithm>partbyday</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
Function标签主要指定分片算法的具体规则。其样例格式如下:
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="partbyday"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sNaturalDay">0</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sEndDate">2014-01-31</property>
<property name="sPartionDay">10</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
server.xml配置文件:
server.xml中配置MyCat的系统信息。聚焦标签于:1.system标签;2.user标签。
system标签主要是系统相关参数和运行时参数。其样例格式如下:
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="ignoreUnknownCommand">0</property><!-- 0遇上没有实现的报文(Unknown command:),就会报错、1为忽略该报文,返回ok报文。
在某些mysql客户端存在客户端已经登录的时候还会继续发送登录报文,mycat会报错,该设置可以绕过这个错误-->
<property name="useHandshakeV10">1</property>
<property name="removeGraveAccent">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequnceHandlerType">1</property>
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
INSERT INTO `travelrecord` (`id`,user_id) VALUES ('next value for MYCATSEQ_GLOBAL',"xxx");
-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">0</property>
<!--
单位为m
-->
<property name="memoryPageSize">64k</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
<!--如果为0的话,涉及多个DataNode的catlet任务不会跨线程执行-->
<property name="parallExecute">0</property>
</system>
系统参数和运行时参数含义表:
| 属性 | 取值 | 含义 |
|---|---|---|
| charset | utf8 | 设置MyCat的字符集,字符集需要育MySQL的字符集保持一致 |
| nonePasswordLogin | 0,1 | 0:需要密码登录,1;不需要密码登录。默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动,是否采用HandshakeV10Packet来与client进行通信,1:是,0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计,1:开启;0:关闭。开启之后,MyCat会自动统计SQL语句执行情况。mysql -h 127.0.0.1 -p 9066 -u root -p查看MyCat执行的SQL,执行效率比较低的SQL,SQL的整体执行情况、读写比例等;show @@sql;show @@sql.slow;show @@sql.sum; |
| useGlobalTableCheck | 0,1 | 是否开启全局表一致性检测。1:开启,0:关闭 |
| sqlExecuteTimeout | 1000 | sql语句执行超时时间,单位为s |
| sequnceHandlerType | 0,1,2 | 用来指定MyCat全局序列类型,0:本地文件,1:数据库方式,2:时间戳列方式,默认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ或mycatseq进入序列匹配流程,注意MYCATSEQ有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段,默认false |
| useCompression | 0,1 | 开启mysql压缩协议,0:关闭,1:开启 |
| fakeMySQLVersion | 5.5.5.6 | 设置模拟的MySQL版本号 |
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB的SQL解析器,在MyCat1.3后增加了Druid解析器,所以要设置defaultSqlParser属性来指定默认的解析器;解析器有两个:druidparser和fdbparser,在MyCat1.4之后,默认是druidparser,fdbparser已经废除了 | |
| process | 1,2… | 指定系统可用的线程数量,默认为CPU核心x每个核心运行线程数量;processors会影响processorBufferPool,processorBufferLocalPercent,processorExecutor属性。所有在性能调优时,可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认值为4096字节,也会影响BufferPool长度,如果一次性获取字节过多而导致Buffer不够用,则会出现警告,可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享businessExecutor固定线程池的大小;MyCat把异步任务交给businessExecutor线程池中,在新版本的MyCat中这个连接池使用的频次不高,可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度,默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小,默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将关闭资源并回收,默认30分钟 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为REPEATED_READ,对应数字为3。READUNCOMMITED=1;READCOMMITTED=2;REPEATED_READ=3;SERIAIZABLE=4 |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间,如果SQL语句执行超时,将关闭连接,默认:300秒 |
| serverPort | 8066 | 定义MyCat的使用端口,默认8066 |
| managerPort | 9066 | 定义MyCat的管理端口,默认9066 |
user标签主要包含用户连接信息。其样例格式如下:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
用户连接信息参数的含义:
- user里面的name:用户名
- name="password"里面的值:密码
- name="schemas"里面的值:该用户可以访问的逻辑库,多个逻辑库之间逗号分隔
- privileges中的check:是否开启DML权限检查,默认为false
- schema和table表中的dml值:0/1共四位对应DML中的IUSD(增加、修改、查询、删除)的权限
- name="readOnly":是否只读,默认为false
3.4 MyCat分片规则
范围分片(rang-long):指定字段及其配置的范围于数据节点的对应情况,来决定数据属于哪一个分片。
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
取模分片(mod-long):指定的字段值与节点数量进行求模运算,根据运算结果,来决定该数据属于哪个分片。
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
一致性Hash(murmur):相同的哈希因子计算值总是会被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置。
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
枚举分片(hash-int):通过在配置文件配置可能的美剧值,指定数据分布到不同数据节点上,适用于: 省份、 性别、 状态拆分数据等业务。
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
应用指定(sharding-by-substring):运行阶段有应用自主决定路由到哪个分片,直接根据子字符串(必须是数字)计算分片号。
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">0</property>
</function>
固定分片Hash算法(sharding-by-long-hash):类似于十进制的求模运算,但是为二进制操作,例如id的低10位与10个1进行&运算。
<tableRule name="sharding-by-long-hash">
<rule>
<columns>id</columns>
<algorithm>sharding-by-long-hash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-long-hash" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">1,1,1</property>
<property name="partitionLength">100,412,512</property>
</function>
固定分片Hash算法的特点:
- 如果是求模,连续的值分片规则会分配到不同的分片节点上;但是固定分片Hash算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
- 可以进行均匀分配,也可以非均匀分配。
- 分片字段必须为数字类型。
字符串Hash解析(sharding-by-stringhash):截取字符串中的指定位置的子字符串,然后进行hash算饭,求取出分片节点值。
<tableRule name=”sharding-by-stringhash>
<rule>
<columns>user_id(//指定分片对象) </columns>
<algorithm>sharding-by-stringhash(//指定分片算法)</algorithm>
</rule>
</tableRule>
<function name="sharding-by-stringhash" class="io.mycat.route.function.PartitionByString">
<property name="partitionlength">512</property>
<property name="partitionCount">2</property>
<property name="hashSlice">0:2</property>
</function>
按天进行分片(partbyday):对日期字段进行按天分片处理。从开始时间,每10天为一个分片,到达结束时间之后,会重复开始分片插入;配置中的dataNode的分片节点,必须和分片规则中计算的数量保持一致。例如2023-01-01到2023-12-32每10天一个分片,则一共需要37个分片。
<tableRule name="sharding-by-date">
<rule>
<columns>createTime</columns>
<algorithm>partbyday</algorithm>
</rule>
</tableRule>
<function name="partbyday"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sNaturalDay">0</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sEndDate">2014-01-31</property>
<property name="sPartionDay">10</property>
</function>
按自然月分片(partbymouth):按照月份来分片,每一个自然月为一个分片。从开始时间,每个月为一个分片,到达结束时间之后,会重复开始分片插入;配置中的dataNode的分片节点,必须和分片规则中计算的数量保持一致。
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2023-01-01</property>
<property name="sEndDate">2023-03-31</property>
</function>
3.5 MyCat管理及监控
MyCat的原理或处理流程如下图:
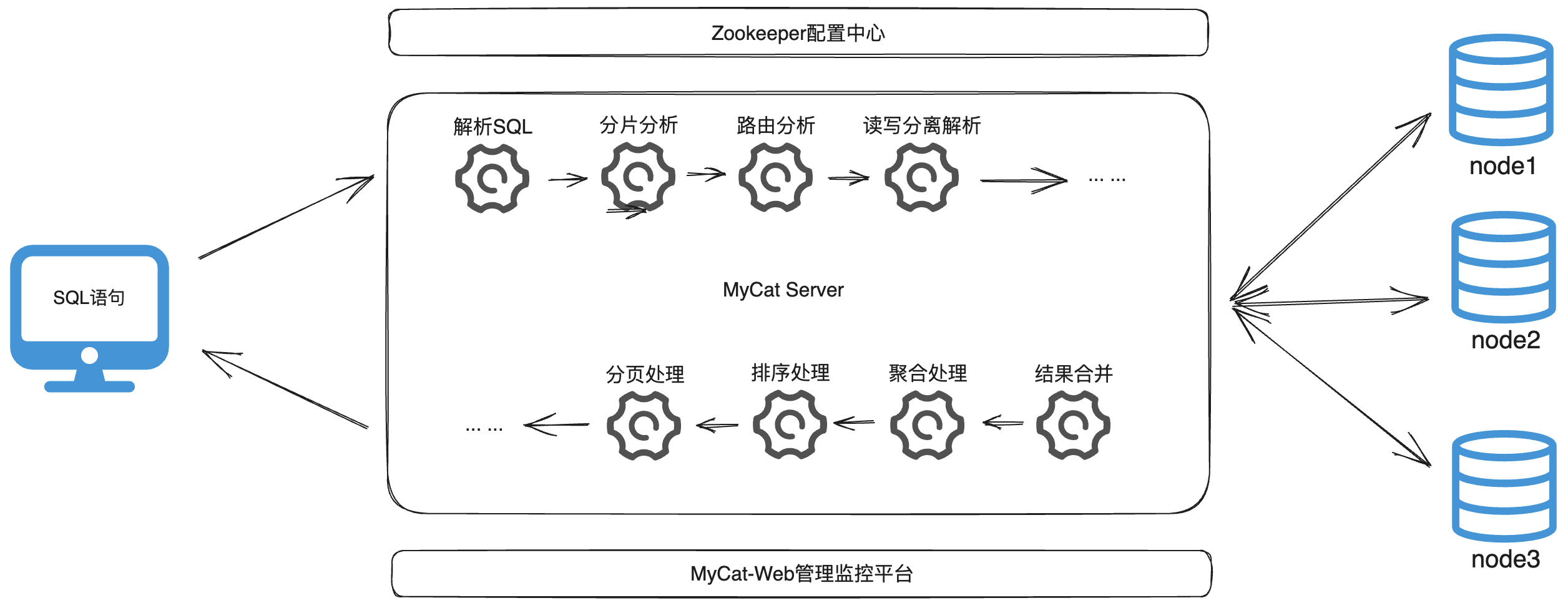
MyCat默认开通2个端口,可以server.xml中进行配置修改。
- 8066端口:数据库访问端口,即进行DML和DDL操作。
- 9066端口:数据库管理端口,即MyCat服务管理控制功能,用于管理MyCat的整个集群状态。
MyCat的数据库管理和访问登陆方式都是一样:
# 数据库访问端口登陆
mysql -h 127.0.0.1 -p 8066 -u 用户名 -p 密码
# 数据库管理端口登陆
mysql -h 127.0.0.1 -p 9066 -u 用户名 -p 密码
MyCat常用管理命令:
| 命令 | 含义 |
|---|---|
| show @@help | 查看MyCat管理工具帮助文档 |
| show @@version | 查看MyCat的版本 |
| reload @@config | 重新加载MyCat的配置文件 |
| show @@datasource | 查看MyCat的数据源信息 |
| show @@datanode | 查看MyCat现有的分片节点信息 |
| show @@threadpool | 查看MyCat的线程池信息 |
| show @@sql | 查看执行的SQL |
| show @@sql.sum | 查看执行的SQL统计 |
3.6 MyCat-Web 图形化监控
MyCat-Web(MyCat-eye)是对MyCat-server提供图形化监控服务,功能并不局限于对MyCat-server使用。它通过JDBC连接对MyCat、 MySQL进行监控。 监控远程服务器的CPU、 内存、 网络、 磁盘。
MyCat-Web运行的环境依赖于:zookeeper。
zookeeper安装:
目录规划:
- 安装包上传目录:/software/
- 安装包解压目录:/software/apache-zookeeper-3.8.2-bin
- 数据存放目录:/software/apache-zookeeper-3.8.2-bin/data
步骤1:下载zookeeper安装包
zookeeper下载页面:https://zookeeper.apache.org/releases.html
zookeeper3.8.2安装包下载:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.8.2/apache-zookeeper-3.8.2-bin.tar.gz
步骤2:上传zookeeper安装包至服务器并解压
# 上传zookeeper安装包
rz
# 解压zookeeper安装包
tar -zxf ./apache-zookeeper-3.8.2-bin.tar.gz
步骤3:创建数据存放
# 进入zookeeper解压目录
cd apache-zookeeper-3.8.2-bin/
# 创建zookeeper的数据存放目录
mkdir ./data
步骤4:拷贝配置文件并重命名配置文件名称
cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
步骤5:在zoo.cfg配置文件中修改数据存放目录
# 修改dataDir路径为zookeeper根目录下的data
dataDir=/software/apache-zookeeper-3.8.2-bin/data
步骤6:启动zookeeper服务
# 启动zookeeper服务
bin/zkServer.sh start
# 查看zookeeper服务状态
bin/zkServer.sh status
MyCat-Web安装:
目录规划:
- 安装包上传目录:/software/
- 安装包解压目录:/software/mycat-web
步骤1:下载MyCat-Web安装包
MyCat-Web安装包下载地址:https://github.com/MyCATApache/Mycat-download/tree/master/mycat-web-1.0
步骤2:上传并解压MyCat-Web安装包
# 上传MyCat-Web安装包
rz
# 解压MyCat-Web安装包
tar -zxf ./mycat-web.tar.gz
步骤3:修改配置文件(默认不需要修改)
vim ./mycat-web/WEB-INF/classes/mycat.properties
步骤4:启动MyCat-Web服务
sh start.sh
步骤5:进入浏览器访问MyCat-Web页面
MyCat-Web页面地址: http://ip:8082/mycat
MyCat-Web的目录结构说明:
- etc:jetty配置文件
- lib:依赖jar包
- mycat-web:mycat-web项目
- readme.txt
- start.jar:启动jar包
- start.sh:启动脚本
4. 读写分离
读写分离就是把数据库的读和写操作分开,以应对不同的数据库服务器。主数据库提供写操作,从数据库提供读操作,更好的减轻了单台数据库的压力。
MyCat可非嵌入式的实现读写分离的功能,不仅支持MySQL,也可以支持Oracle和SQL Server。
MyCat控制后台数据库读写分离和负载均衡是由schema.xml文件的datahost标签中的balance属性控制。通过writeType及switchType来完成失败自动切换。
balance负载均衡策略的四种取值及其含义:
| 参数值 | 含义 |
|---|---|
| 0 | 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上 |
| 1 | 全部的readHost与备用的writeHost都参与select语句的负载均衡(主要针对于双主双从模式) |
| 2 | 所有的读写操作都随机在wirteHost,readHost上分发 |
| 3 | 所有的读请求随机分发到writeHost对应的readHost上执行,writeHost不负担读压力 |
writeType取值及其含义:
| 参数值 | 含义 |
|---|---|
| 0 | 写入操作都转发到第一个writeHost节点上。如果当前writeHost节点出现故障,会切换到下一个writeHost节点上。 |
| 1 | 所有的写操作都随机发送到配置writeHost节点上。 |
switchType取值及其含义:
| 参数值 | 含义 |
|---|---|
| -1 | 不自动切换 |
| 1 | 自动切换 |
4.1 一主一从读写分离
MyCat实现一主一从读写分离示意图:
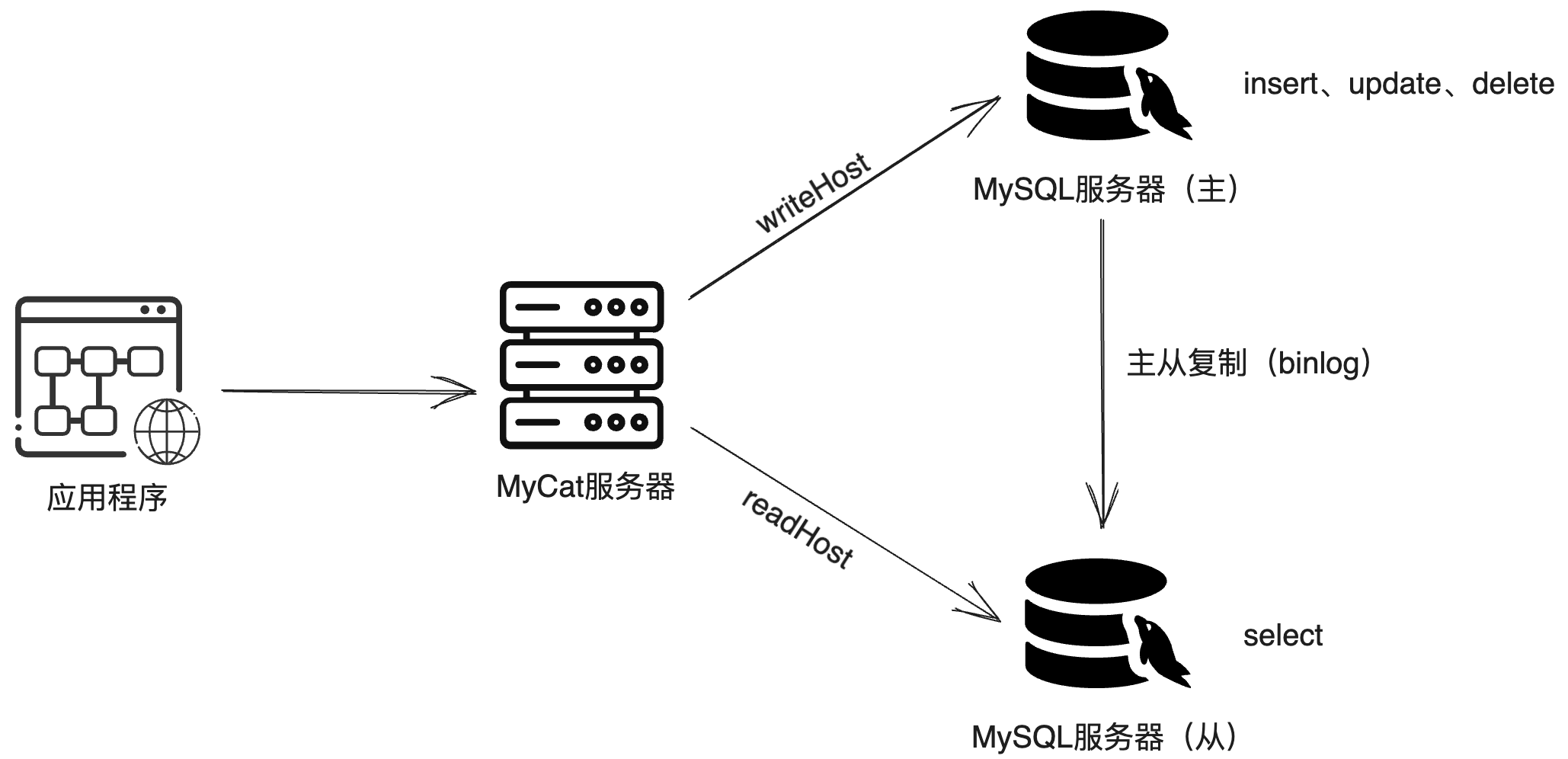
环境准备:
- 两台MySQL服务器且具备主从复制功能。
- 一台MyCat服务器(可以与一台MySQL服务共用)。
一主一从读写分离搭建:
MyCat控制后台数据库读写分离和负载均衡是由schema.xml文件的datahost标签中的balance属性控制。
步骤1:修改配置信息
schema.xml配置文件:
<!-- schame中的table标签可以不声明,会自动的找到实际test数据库的所有表进行加载 -->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="testdb">
</schema>
<dataNode name="testdb" dataHost="localhost1" database="test" />
<!-- balance的值设置为1、 3都可以实现一主一从的读写分离 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="localhost:3306" user="root" password="123456">
<readHost host="slave" url="localhost:3307" user="root" password="123456" />
</writeHost>
</dataHost>
server.xml配置文件:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
</user>
步骤2:重启MyCat服务
# 停止
mycat stop
# 启动
mycat start
一主一从读写分离验证:
- 在从数据库修改某个数据库表的字段的值后,在MyCat中进行查询操作,比较当前修改字段的值是否为修改之后的,如果是修改之后的,即可验证为读取的是readhost节点。
- 在MyCat中进行插入数据操作,查看数据库中的主从数据节点是否同时有数据,如果都存在数据,即可验证为是写入writeHost节点。
一主一从的读写分离存在的问题:主节点master宕机之后,业务系统就只能够读,而不能写入数据。
4.2 双主双从读写分离
MyCat实现双主双从读写分离示意图:
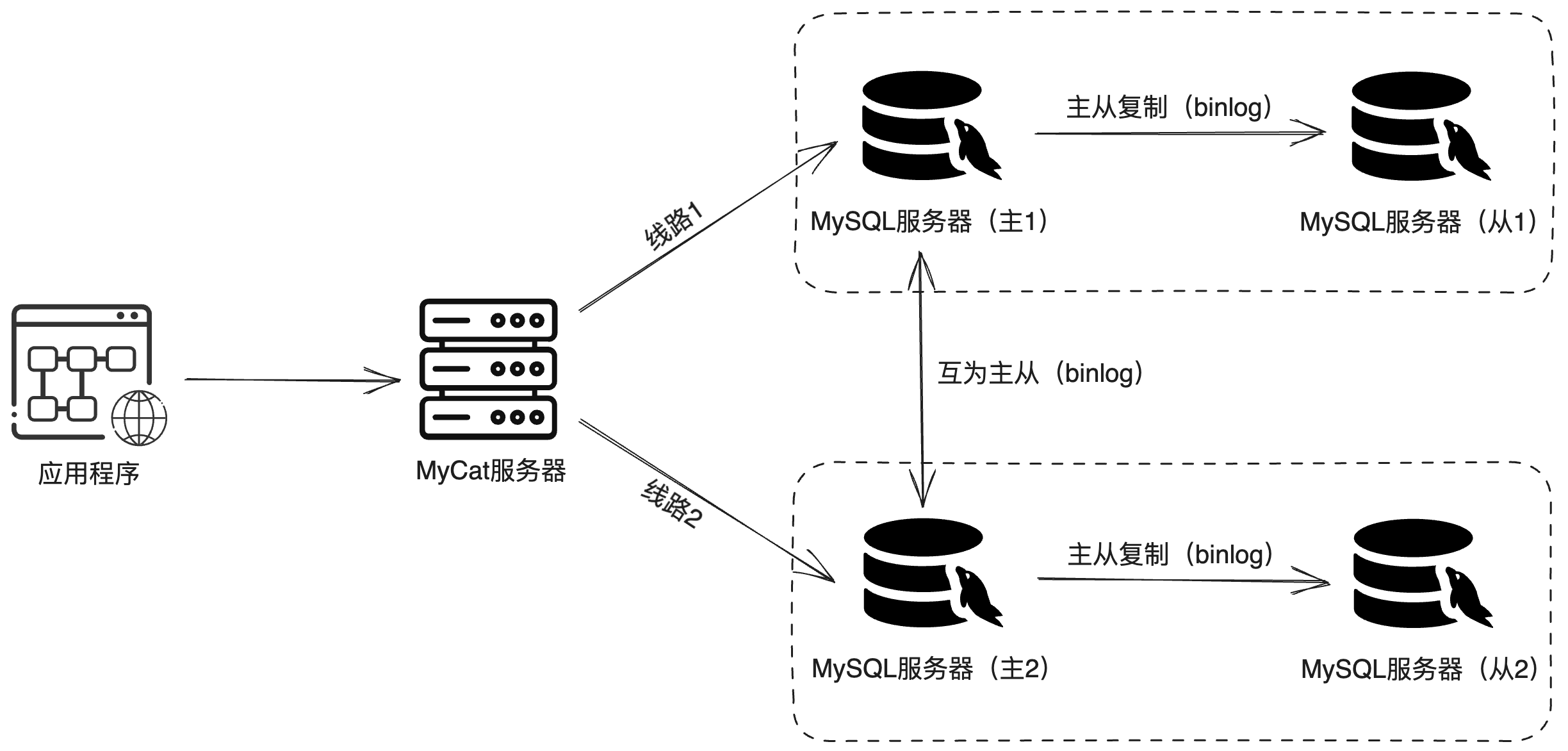
环境准备:
- 四台MySQL服务器,分为两组。每组内部具备主从复制功能。每组之间互为主从复制。
- 一台MyCat服务器(可以与一台MySQL服务共用)。
互为主从复制时的注意点:在修改配置my.cnf配置文件时,需要在互为主从中加入log-slave-updates参数。
# mysql 服务ID,保证整个集群环境中唯一,取值范围:1 - 2^32-1。默认为1
server-id=1
# 是否只读,1 代表只读,0 代表读写
read-only=0
# 忽略的数据,指不需要同步的数据库
#binlog-ignore-db=mysql
# 指定同步的数据库
#binlog-do-db=db01
# 作为从数据库的时候,有写入操作时,也需要更新二进制日志文件
log-slave-updates
双主双从读写分离搭建:
MyCat控制后台数据库读写分离和负载均衡是由schema.xml文件的datahost标签中的balance属性控制。通过writeType及switchType来完成失败自动切换。
步骤1:修改配置信息
schema.xml配置文件:
<!-- schame中的table标签可以不声明,会自动的找到实际test数据库的所有表进行加载 -->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="testdb">
</schema>
<dataNode name="testdb" dataHost="localhost1" database="test" />
<!-- balance的值设置为1,实现双主双从的读写分离。 -->
<!-- writeType的值设置为0,实现从首个可用的writeHost节点上写入操作,如果出现故障,则切换到下一个可用的节点上。 -->
<!-- switchType的值设置为1,实现自动切换。 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" switchType="1" dbType="mysql" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="localhost:3306" user="root" password="123456">
<readHost host="slave1" url="localhost:3307" user="root" password="123456" />
</writeHost>
<writeHost host="master2" url="localhost:3308" user="root" password="123456">
<readHost host="slave2" url="localhost:3309" user="root" password="123456" />
</writeHost>
</dataHost>
server.xml配置文件:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
</user>
步骤2:重启MyCat服务
# 停止
mycat stop
# 启动
mycat start
双主双从读写分离验证:
- 通过数据库管理软件,所有的从数据库修改某一个表的字段值(修改的字段相同),在MyCat中进行多次查询操作,比较当前修改字段的值是否为修改之后的,如果是修改之后的,即可验证为读取的节点位置。
- 在MyCat中进行插入数据操作,查看数据库中的主从数据节点是否同时有数据,如果都存在数据,即可验证为是写入节点位置。
双主双从的读写分离解决一主一从存在的问题:如果当前数据库的写入服务器节点出现问题,那么会自动切换到下一个数据库的写入节点,以保证数据库的高可用性。
评论区